Cloudflare Stream introduces automatic captions powered by AI
Effortless caption generation for on-demand videos and live stream recordings.

Effortless caption generation for on-demand videos and live stream recordings.
Cloudflare today unveiled a new feature for its Stream video platform: automatic caption generation using artificial intelligence (AI). This beta feature is available to all Stream customers at no additional cost, aligning with Cloudflare's mission of fostering a more accessible internet.
The new feature eliminates the need for third-party caption services and complex workflows, a common pain point for video creators. Traditionally, caption generation involved specialized services or dedicated teams, making it a time-consuming and resource-intensive task, especially for large video libraries. Stream's integrated solution simplifies the process, allowing users to add captions to existing videos with a few clicks directly within the Cloudflare dashboard or via an API.
Stream's AI-powered caption generation prioritizes user privacy. Unlike some third-party services, user data remains secure within the Cloudflare ecosystem throughout the process. Cloudflare does not utilize user content for model training purposes. More information on data protection can be found in the Cloudflare resource "Your Data and Workers AI."
As of June 20, 2024, all Stream customers and subscribers of the Professional and Business plans (which include 100 minutes of video storage) have access to the beta feature.
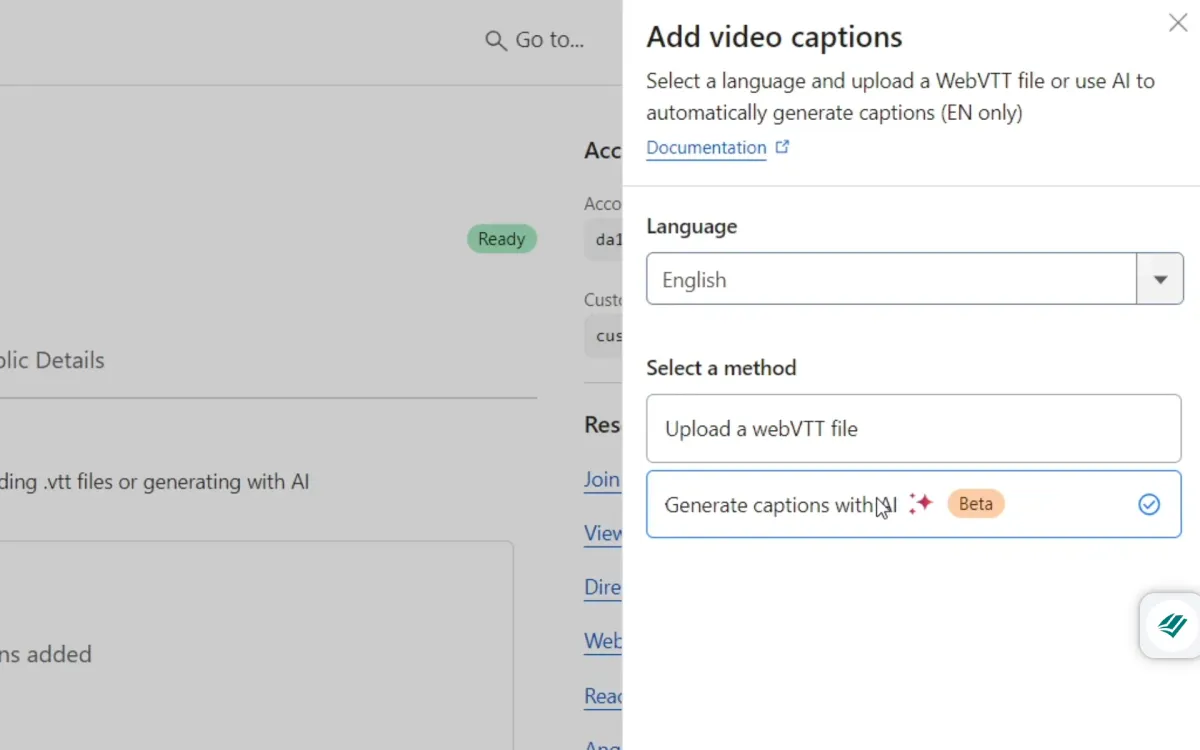
Here's a quick guide to using automatic captions:
Alternatively, captions can be generated through the Stream API.
Currently, the beta version supports English captions only for on-demand videos and recordings of live streams, regardless of upload date. Video length is limited to under 2 hours, and the best transcription quality is achieved with clear audio and minimal background noise. While internal testing has shown promising results, Cloudflare acknowledges that the AI model may not be perfect in all cases, and users should review the generated captions for accuracy.
Cloudflare says the development team is focused on expanding language options and increasing supported video lengths in future updates.
The Stream engineering team leveraged Cloudflare Workers AI to access Whisper, an open-source automatic speech recognition (ASR) model. Workers AI simplified the deployment, integration, and scaling of the AI model by providing a ready-made solution. This eliminated the need for complex infrastructure management, allowing the team to focus on building the captioning feature.
Deploying AI models traditionally involves challenges like configuring appropriate hardware and managing complexities like workload distribution, latency, and high availability. Workers AI addresses these challenges by providing a scalable and infrastructure-managed environment.
With Workers AI, the caption generation process was condensed into a Worker script requiring less than 30 lines of code. The script utilizes the "@cloudflare/ai" library to interact with the Whisper model via a single API call.
The Stream team prioritized fast and scalable caption generation for a high volume of videos. This involved preprocessing the audio data before feeding it to the AI model for efficient inference.
Video content varies greatly, from short phone recordings to feature-length films. Videos can be silent, contain background noise, or be live stream recordings with different packaging formats compared to uploaded files. Stream's solution addresses this variability by ensuring audio inputs are compatible with Whisper's requirements.
Preprocessing involves segmenting audio into optimal durations for efficient inference. Whisper performs best with 30-second audio batches, as discussed in a GitHub thread where developers note: "Shorter clips lack context, while longer ones require larger models to handle complexity." Fortunately, Stream already segments videos for optimized playback, and the team built functionality to combine these segments into 30-second batches before sending them to Workers AI.
To further optimize processing speed, the team parallelized operations as much as possible. This means creating audio batches and sending requests to Workers AI concurrently, maximizing the platform's scalability. While this approach significantly reduces caption generation time, it introduces the complexity of handling potentially out-of-order transcription responses. For instance, captions for the second half of a video might arrive before captions for the first half. To ensure proper synchronization with the video, the team developed a system to sort incoming responses and reorder timestamps, resulting in an accurate final WebVTT caption file.