John Mueller, Senior Search Analyst at Google, this week provided clarification on a perplexing issue faced by webmasters: the indexing of pages blocked by robots.txt. This explanation came in response to a question posed by SEO professional Rick Horst on LinkedIn, shedding light on Google's handling of such pages and offering valuable insights for website owners and SEO practitioners.
The discussion centered around a scenario where bots were generating backlinks to non-existent query parameter URLs, which were subsequently being indexed by Google despite being blocked by robots.txt and having a "noindex" tag. Mueller's responses provided a comprehensive explanation of how Google's crawling and indexing processes work in such situations.
Understanding the Core Issue
Rick Horst described a situation where:
- Bots were generating backlinks to query parameter URLs (?q=[query]) that didn't exist on the website.
- These pages were blocked in the robots.txt file.
- The pages also had a "noindex" tag.
- Google Search Console showed these pages as "Indexed, though blocked by robots.txt."
The central question was: Why would Google index pages when it can't even see the content, and what advantage does this serve?
John Mueller's Explanation
Mueller provided a detailed response, breaking down several key points:
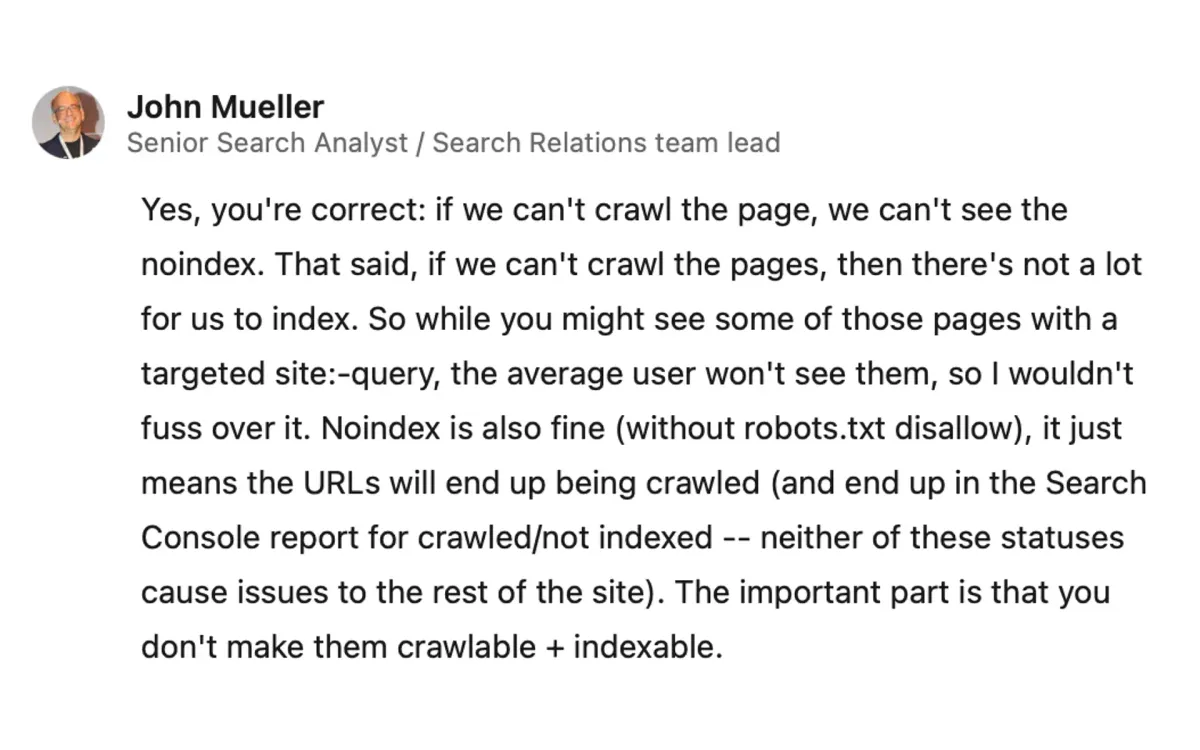
- Robots.txt vs. Noindex: Mueller confirmed that if Google can't crawl a page due to robots.txt restrictions, it also can't see the noindex tag. This explains why pages blocked by robots.txt but containing a noindex tag might still be indexed.
- Limited Indexing: Mueller emphasized that if Google can't crawl the pages, there's not much content to index. He stated, "While you might see some of those pages with a targeted site:-query, the average user won't see them, so I wouldn't fuss over it."
- Noindex Without Robots.txt Block: Mueller explained that using noindex without a robots.txt disallow is fine. In this case, the URLs will be crawled but end up in the Search Console report for "crawled/not indexed." He assured that neither of these statuses causes issues for the rest of the site.
- Importance of Crawlability and Indexability: Mueller stressed, "The important part is that you don't make them crawlable + indexable."
- Robots.txt as a Crawling Control: In a follow-up comment, Mueller clarified that robots.txt is a crawling control, not an indexing control. He stated, "The robots.txt isn't a suggestion, it's pretty much as absolute as possible (as in, if it's parseable, those directives will be followed)."
- Common Search Form Abuse: Mueller acknowledged that this kind of search-form-abuse is common and advised leaving the pages blocked by robots.txt, suggesting that it generally doesn't cause issues.
Implications for Webmasters and SEO Professionals
Mueller's explanations have several important implications:
- Robots.txt Limitations: While robots.txt can prevent crawling, it doesn't necessarily prevent indexing, especially if there are external links to the page.
- Noindex Tag Effectiveness: For the noindex tag to be effective, Google needs to be able to crawl the page. Blocking a page with robots.txt while also using a noindex tag is counterproductive.
- Handling Bot-Generated URLs: For websites facing issues with bot-generated URLs, using robots.txt to block these pages is generally sufficient and won't cause problems for the rest of the site.
- Search Console Reports: Webmasters should be aware that pages blocked by robots.txt might still appear in certain Search Console reports, but this doesn't necessarily indicate a problem.
- Balancing Crawl Control and Indexing: Website owners need to carefully consider their strategy for controlling crawling and indexing, understanding that these are separate processes in Google's system.
Key Takeaways
- Robots.txt blocks crawling but doesn't guarantee prevention of indexing.
- Noindex tags are only effective if Google can crawl the page.
- For complete exclusion from search results, allow crawling but use noindex.
- Bot-generated URLs can often be safely blocked with robots.txt.
- Google may index uncrawled pages based on external link information.
Facts Summary
- Date of Discussion: September 5, 2024
- Main Participants: John Mueller (Google), Rick Horst (SEO Professional)
- Platform: LinkedIn
- Key Issue: Indexing of pages blocked by robots.txt
- Google's Stance: Robots.txt is a crawling control, not an indexing control
- Recommended Approach: Use noindex without robots.txt block for pages you don't want indexed
- Common Problem: Bot-generated backlinks to non-existent query parameter URLs
- Search Console Status: "Indexed, though blocked by robots.txt" for affected pages
- Mueller's Advice: Don't worry about pages visible only in site:-queries
- Technical Distinction: Crawling and indexing are separate processes in Google's system
Share this article
The link has been copied!