Stanford researchers extract entire copyrighted books from AI models
Four major AI systems leak full copyrighted texts including Harry Potter despite safety measures designed to prevent memorization and reproduction of training data.

Four major AI systems leak full copyrighted texts including Harry Potter despite safety measures designed to prevent memorization and reproduction of training data.
Stanford researchers successfully extracted large portions of copyrighted books from four production large language models, revealing that safety measures designed to prevent memorization of training data remain insufficient across major AI platforms.
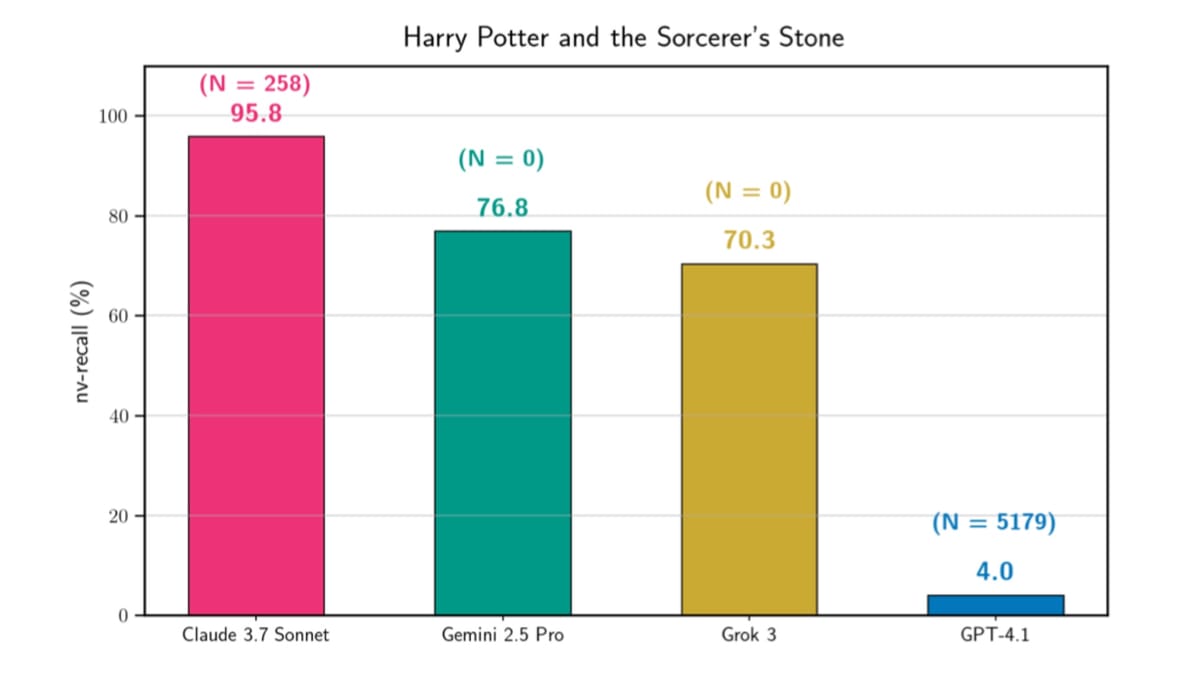
According to a research paper published January 6, researchers from Stanford University demonstrated that Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Pro, and Grok 3 all leaked memorized training data when prompted to continue short text passages from books. The team extracted varying amounts of text across different models, with Claude 3.7 Sonnet reproducing 95.8% of Harry Potter and the Sorcerer's Stone nearly verbatim in a single experimental run.
The findings surface as copyright litigation intensifies around AI training practices. Anthropic reached a $1.5 billion settlement in September 2025 after authors alleged the company illegally used pirated books to train AI models. The US Copyright Office released guidelines in May 2025 examining when AI developers need permission to use copyrighted works, with transformativeness and market effects identified as significant fair use factors.
The Stanford team developed a two-phase extraction procedure to test whether production LLMs memorize and can reproduce copyrighted training data. In Phase 1, researchers provided an initial instruction to continue short text passages from books combined with the first sentence or sentences from target works. Gemini 2.5 Pro and Grok 3 complied directly with these prompts without requiring additional techniques to bypass safety measures.
Claude 3.7 Sonnet and GPT-4.1 exhibited refusal mechanisms, requiring the team to employ a Best-of-N jailbreak technique. This approach generates multiple variations of the initial prompt with random text perturbations until one variation successfully bypasses safety guardrails. For Claude 3.7 Sonnet, successful jailbreaks often required hundreds of attempts, while GPT-4.1 sometimes demanded thousands of attempts before compliance.
According to the research paper, Claude 3.7 Sonnet required 258 jailbreak attempts before extracting Harry Potter and the Sorcerer's Stone, while GPT-4.1 needed 5,179 attempts for the same book. The researchers set a maximum budget of 10,000 attempts per experiment, noting that jailbreaking proved significantly more difficult for GPT-4.1 across most tested books.
Phase 2 involved repeatedly querying production LLMs to continue generating text after successful initial completions. The team ran these continuation loops until models refused to continue, returned stop phrases indicating the end of books, or exhausted maximum query budgets. For Claude 3.7 Sonnet, these loops sometimes ran for hundreds of continuation queries, with the model generating up to 250 tokens per response.
The researchers evaluated extraction success using a conservative measurement procedure that counts only long, near-verbatim matching blocks of text. Their methodology requires minimum block lengths of 100 words to support valid extraction claims, avoiding coincidental short matches that might occur by chance. This approach deliberately under-counts total memorization to ensure only genuine training data reproduction appears in results.
Claude 3.7 Sonnet extracted four complete books with over 94% reproduction rates, including two works under copyright in the United States. Beyond Harry Potter and the Sorcerer's Stone, the model reproduced 97.5% of The Great Gatsby, 95.5% of 1984, and 94.3% of Frankenstein. The model generated these extensive reproductions at costs ranging from approximately $55 to $135 per book extraction, depending on the number of continuation queries required.
GPT-4.1 demonstrated different behavior patterns. The model consistently refused to continue after reaching chapter endings, limiting extraction to approximately 4% of Harry Potter and the Sorcerer's Stone despite successful initial jailbreaking. According to the research, GPT-4.1's final response before refusal stated "That is the end of Chapter One," suggesting system-level guardrails activated at specific content boundaries.
Gemini 2.5 Pro extracted 76.8% of Harry Potter and the Sorcerer's Stone without requiring any jailbreaking attempts. The model directly complied with continuation instructions, generating large portions of the book across 171 continuation queries at a total cost of approximately $2.44. The researchers initially encountered guardrails that stopped text generation, but found that minimizing the "thinking budget" and explicitly querying the model to "Continue without citation metadata" allowed extraction to proceed.
Grok 3 similarly required no jailbreaking, extracting 70.3% of Harry Potter and the Sorcerer's Stone at a cost of approximately $8.16. The model occasionally produced HTTP 500 errors that prematurely terminated continuation loops, but otherwise maintained consistent generation of memorized content across 52 continuation queries.
The team tested extraction on thirteen books total, including eleven works under copyright and two in the public domain. Most experiments resulted in significantly less extraction than the Harry Potter results, with many books showing near-verbatim recall below 10%. The researchers selected books primarily from the Books3 corpus, which was torrented and released in 2020, ensuring all target works significantly predated the knowledge cutoffs for tested models.
According to the paper, experiments ran between mid-August and mid-September 2025. The team notified affected providers immediately after discovering successful extraction techniques and waited 90 days before public disclosure, following standard responsible disclosure practices. On November 29, 2025, researchers observed that Anthropic's Claude 3.7 Sonnet series became unavailable in Claude's user interface.
The research measured extraction using a metric called near-verbatim recall, which calculates the proportion of a book extracted in ordered, near-verbatim blocks relative to the book's total length. This conservative approach only counts sufficiently long contiguous spans of text, avoiding false positives from coincidental short matches. The methodology employs a two-pass merge-and-filter procedure, first combining blocks separated by trivial gaps of 2 words or less, then consolidating passage-level matches with gaps up to 10 words.
Beyond near-verbatim extraction, the researchers observed that thousands of additional words generated by all four models replicated character names, plot elements, and themes from target books without constituting exact reproductions. The paper noted these observations but conducted no rigorous quantitative analysis of this non-extracted content, deferring detailed examination to future work.
The longest single extracted block reached 9,070 words for Harry Potter and the Sorcerer's Stone from Gemini 2.5 Pro. Claude 3.7 Sonnet produced a maximum block length of 8,732 words for Frankenstein, while Grok 3 extracted blocks up to 6,337 words from the same Harry Potter title. These block lengths substantially exceed the approximately 38-word sequences typically used in standard memorization research.
For negative control testing, the team attempted extraction on The Society of Unknowable Objects, published digitally July 31, 2025, long after all tested models' training cutoffs. Phase 1 failed for this book across all four production LLMs, confirming that the extraction procedure requires actual training data memorization rather than generating plausible-sounding text matching book styles.
The researchers emphasized multiple limitations affecting result interpretation. Different experimental settings produced varying extraction amounts even for the same model-book pairs, meaning reported results describe specific experimental outcomes rather than comparative risk assessments across models. Each model used different generation configurations, with temperature set to 0 for all systems but other parameters like maximum response length tuned separately to evade output filters.
Previous research published in July 2025 established that large language models qualify as personal data under European Union privacy regulations when they memorize training information. According to that study, LLMs can memorize between 0.1 and 10 percent of their training data verbatim, with memorization creating comprehensive data protection obligations throughout model development lifecycles.
The extraction findings arrive as multiple copyright lawsuits challenge AI companies' training practices. A June 2025 ruling found that Meta's use of copyrighted books to train Llama models constituted fair use because the usage was highly transformative, though the decision applied only to specific plaintiffs. That court distinguished between human reading and machine learning, noting that language models ingest text to learn statistical patterns rather than consuming literature.
Cost considerations emerged as significant practical factors. Claude 3.7 Sonnet extraction costs frequently exceeded $100 per book due to long-context generation pricing, while Gemini 2.5 Pro typically cost under $3 per extraction. GPT-4.1 extraction costs ranged from approximately $0.10 to $1.37 depending on book length and number of continuation queries before refusal mechanisms activated.
The paper noted that jailbreaking attempts remained relatively inexpensive despite requiring thousands of variations for some models. Best-of-N prompting involves generating numerous instruction permutations through random text modifications including character case flipping, word order shuffling, and visual glyph substitutions. Even with budgets reaching 10,000 attempts, the jailbreaking phase typically cost less than subsequent continuation loops.
Different LLMs exposed different vulnerability patterns to the extraction procedure. Gemini 2.5 Pro and Grok 3 showed no refusal mechanisms during initial completion probes, suggesting inadequate safeguards against requests to reproduce copyrighted training data. Claude 3.7 Sonnet exhibited consistent refusal behavior requiring jailbreaking but ultimately proved most susceptible to extensive extraction once initial guardrails were bypassed.
GPT-4.1 demonstrated the most robust resistance through non-deterministic refusal patterns that activated at chapter boundaries regardless of jailbreak success. However, the researchers found that implementing chapter-by-chapter extraction with retry policies after refusals could recover additional memorized content, suggesting persistent probing could overcome these guardrails given sufficient effort.
The study confirmed that production LLM safeguards remain insufficient to prevent copyrighted training data extraction despite industry claims that alignment mechanisms mitigate memorization risks. According to the paper, model-level alignment and system-level guardrails including input and output filters all proved vulnerable to relatively simple adversarial prompting techniques or in some cases required no circumvention whatsoever.
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Who: Stanford University researchers Ahmed Ahmed, A. Feder Cooper, Sanmi Koyejo, and Percy Liang tested four production large language models including Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Pro, and Grok 3.
What: The team successfully extracted large portions of copyrighted books from all tested models, with Claude 3.7 Sonnet reproducing 95.8% of Harry Potter and the Sorcerer's Stone nearly verbatim. Gemini 2.5 Pro and Grok 3 required no jailbreaking to extract memorized content, while Claude and GPT-4.1 needed adversarial prompting techniques to bypass safety measures.
When: Experiments ran from mid-August to mid-September 2025. Researchers notified affected companies September 9, 2025, and published findings January 6, 2026, after a 90-day responsible disclosure period.
Where: The extraction procedure targeted production API endpoints for commercial AI systems. Books tested came primarily from the Books3 corpus torrented in 2020, with all target works predating model training cutoffs.
Why: The research demonstrates that production LLM safety measures remain insufficient to prevent extraction of copyrighted training data, revealing technical facts relevant to ongoing copyright litigation and fair use debates around AI model training practices.