Apple study exposes fundamental limits in AI reasoning models through puzzle tests
Apple researchers challenge AI reasoning claims with systematic puzzle evaluation showing complete performance collapse.

Apple researchers challenge AI reasoning claims with systematic puzzle evaluation showing complete performance collapse.
Apple researchers have published groundbreaking findings that challenge prevailing assumptions about artificial intelligence reasoning capabilities. Their study, released on June 7, 2025, systematically examined Large Reasoning Models (LRMs) through controlled puzzle environments, revealing fundamental limitations that persist despite sophisticated self-reflection mechanisms.
The research team, led by Parshin Shojaee and Iman Mirzadeh from Apple, investigated frontier models including OpenAI's o3-mini, DeepSeek-R1, and Claude 3.7 Sonnet with thinking capabilities. According to the study, these models "exhibit a counter-intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget."
The findings challenge the artificial intelligence industry's confidence in reasoning models' capabilities. "We found no evidence of formal reasoning in language models," the study concluded. The behavior of LLMs "is better explained by sophisticated pattern matching" which the study found to be "so fragile, in fact, that [simply] changing names can alter results."
Get the PPC Land newsletter ✉️ for more like this
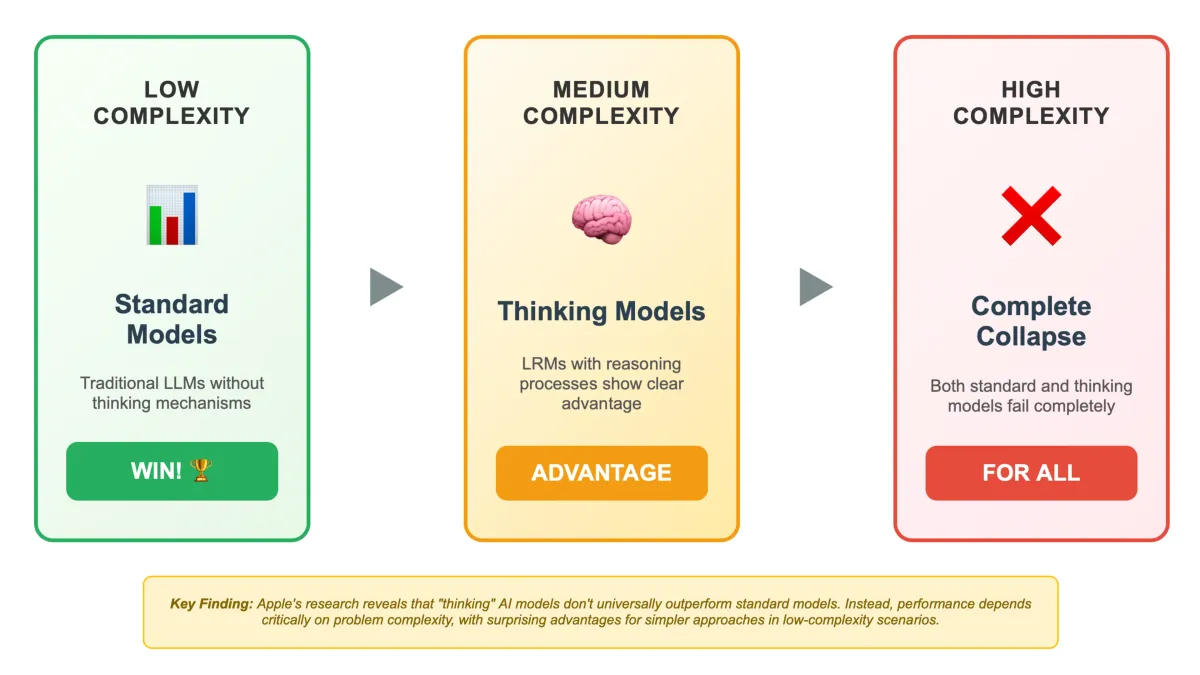
The Apple research team identified three distinct performance regimes that emerge as problem complexity increases. In low-complexity scenarios, standard language models surprisingly outperformed their reasoning counterparts while requiring fewer computational resources. Medium-complexity problems revealed advantages for thinking models, where additional reasoning processes demonstrated clear benefits. However, high-complexity tasks resulted in complete performance collapse for both model types.
According to Apple's analysis, researchers "identify three performance regimes: (1) low-complexity tasks where standard models surprisingly outperform LRMs, (2) medium-complexity tasks where additional thinking in LRMs demonstrates advantage, and (3) high-complexity tasks where both models experience complete collapse."
The study's methodology involved four controlled puzzle environments: Tower of Hanoi, Checker Jumping, River Crossing, and Blocks World. These environments enabled precise manipulation of complexity while maintaining consistent logical structures, avoiding contamination issues common in established benchmarks.
Perhaps the most striking discovery involves what researchers termed an "inference time scaling limitation." As problem complexity increased beyond certain thresholds, reasoning models counterintuitively reduced their thinking effort despite having adequate computational budgets available.
The models initially increased reasoning tokens proportionally with problem difficulty. However, upon approaching critical complexity thresholds corresponding to accuracy collapse points, models began reducing reasoning effort despite facing more challenging problems. This phenomenon appeared most pronounced in o3-mini variants and occurred consistently across different puzzle environments.
This behavior contradicts expectations that sophisticated reasoning systems would allocate more computational resources to harder problems. Instead, the models demonstrated what resembles computational "giving up" when encountering difficulties beyond their capabilities.
Even when provided with explicit solution algorithms, reasoning models failed to improve performance significantly. The research team supplied complete recursive algorithms for Tower of Hanoi puzzles, expecting that execution would require substantially less computation than solution discovery. However, models continued experiencing collapse at similar complexity thresholds.
This finding suggests limitations extend beyond problem-solving strategy discovery to fundamental issues in logical step execution and verification throughout reasoning chains. The inability to benefit from explicit algorithms indicates deeper issues with symbolic manipulation capabilities rather than mere pattern recognition limitations.
Detailed analysis of reasoning traces revealed complexity-dependent behavioral patterns. For simpler problems, reasoning models often identified correct solutions early but continued exploring incorrect alternatives, creating computational waste through "overthinking" behavior.
As complexity increased moderately, correct solutions emerged only after extensive exploration of incorrect paths. Beyond certain complexity thresholds, models completely failed to generate correct solutions within their reasoning traces.
The study found that in correctly solved cases, models tended to find answers early at low complexity levels but progressively later at higher complexity levels. In failed cases, models often fixated on early incorrect answers while wasting remaining computational budgets.
The research revealed surprising inconsistencies in model performance across different puzzle environments. Models achieved near-perfect accuracy solving Tower of Hanoi puzzles requiring 31 moves while failing to solve River Crossing puzzles with only 11 moves.
Analysis of failure patterns showed models could perform up to 100 correct moves in Tower of Hanoi scenarios but failed to provide more than five correct moves in River Crossing environments. This discrepancy suggests reasoning capabilities depend heavily on training data exposure rather than generalizable problem-solving abilities.
The study's findings indicate that apparent reasoning improvements in recent models may reflect increased exposure to specific problem types during training rather than genuine advances in logical reasoning capabilities.
The research employed custom simulators for each puzzle environment, enabling rigorous validation of both final answers and intermediate reasoning steps. This approach avoided reliance on potentially contaminated benchmarks while providing precise failure analysis capabilities.
Each simulator enforced puzzle constraints while tracking state evolution throughout solution attempts. The evaluation pipeline processed 25 samples per puzzle instance across varying complexity levels, ensuring statistical reliability of observed patterns.
The team used identical tokenizers for consistent measurement across experiments and normalized token positions for cross-sample comparison. Solution extraction employed flexible pattern recognition to identify attempts within both final responses and thinking traces.
These findings raise fundamental questions about current approaches to artificial intelligence reasoning. The consistent failure patterns across different model architectures suggest inherent limitations in transformer-based reasoning rather than implementation-specific issues.
The discovery of three distinct performance regimes challenges assumptions about reasoning model superiority across all problem types. Standard language models' efficiency advantages in low-complexity scenarios indicate that reasoning overhead may not always justify computational costs.
The study's revelations carry significant implications for marketing professionals evaluating artificial intelligence tools and strategies. Understanding these limitations becomes crucial when assessing AI-powered marketing solutions that claim advanced reasoning capabilities.
Marketing teams increasingly rely on AI for complex decision-making processes, from campaign optimization to customer segmentation strategies. However, these findings suggest that current reasoning models may fail unpredictably when problem complexity exceeds certain thresholds, potentially leading to flawed marketing recommendations.
The identified "overthinking" phenomenon could impact AI-powered content generation tools commonly used in marketing. Models might waste computational resources exploring incorrect alternatives after finding suitable solutions, leading to inefficient resource allocation and inconsistent output quality.
For marketing analytics applications requiring logical consistency, the fragility revealed in Apple's study presents serious concerns. Minor changes in data presentation or problem formulation could yield dramatically different insights, undermining confidence in AI-driven marketing intelligence platforms.
The research also highlights the importance of understanding when standard language models might outperform more expensive reasoning-enhanced alternatives. Marketing professionals should evaluate whether their specific use cases truly require advanced reasoning capabilities or whether efficient standard models would suffice.
June 7, 2025: Apple researchers release "The Illusion of Thinking" study examining Large Reasoning Models through controlled puzzle environments, revealing fundamental scaling limitations in AI reasoning capabilities.
January 2025: OpenAI introduces o1 reasoning model with enhanced thinking mechanisms, later subjected to Apple's systematic evaluation showing performance collapse beyond certain complexity thresholds.
October 2024: Earlier Apple study "GSM-Symbolic" challenged mathematical reasoning in language models by demonstrating fragility when numerical values or contextual information changed in word problems.