On December 3, 2024, Google released detailed documentation explaining the intricacies of its web crawling process, shedding light on how Googlebot discovers and processes web content. The document, published four days ago on the Google Search Central Blog, provides technical insights into the mechanisms that enable web pages to appear in search results.
According to Martin Splitt and Gary Illyes, who authored the document, crawling represents the initial phase of getting content into Google Search. The process involves Googlebot, a specialized program operating on Google's servers, which manages the complexities of network errors and redirects while systematically working through the web.
The documentation clarifies that modern websites utilize multiple technologies beyond HTML, incorporating JavaScript and CSS to deliver enhanced functionality. When processing these complex pages, Googlebot follows a structured approach that mirrors but differs from standard web browsers.
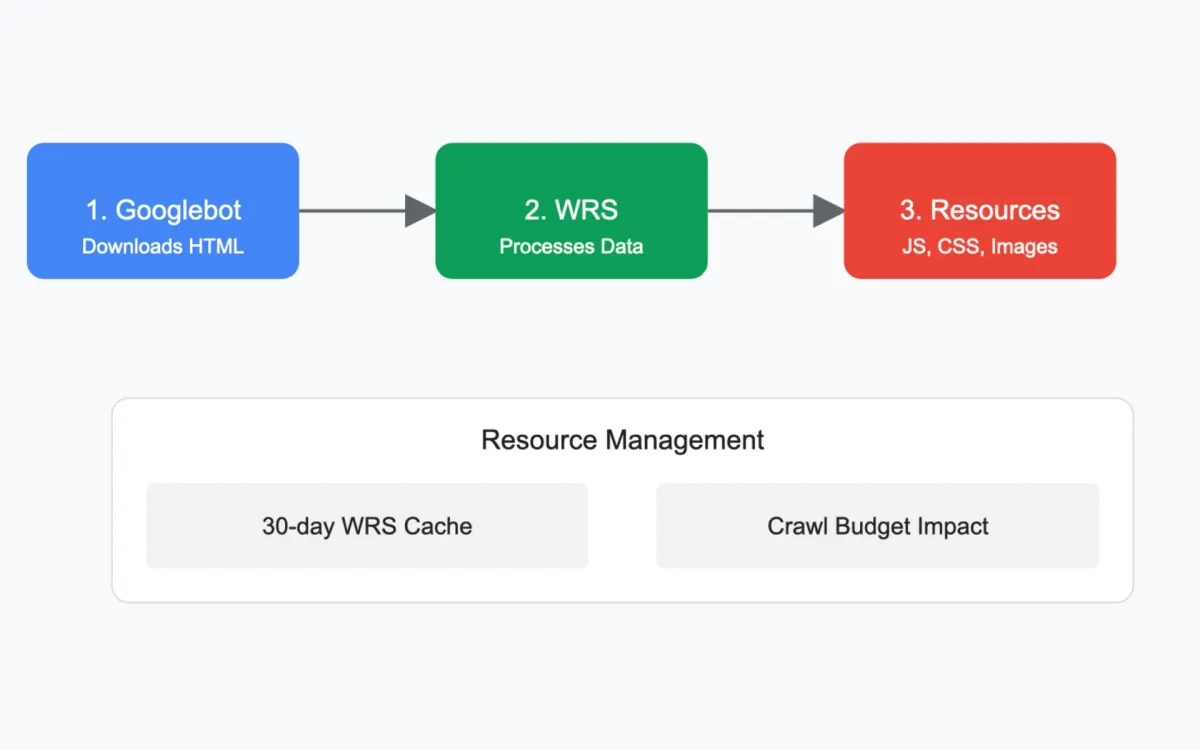
The technical process unfolds in four distinct stages. Initially, Googlebot retrieves the HTML data from the parent URL. This data is then transferred to Google's Web Rendering Service (WRS). Subsequently, WRS employs Googlebot to download referenced resources, and finally constructs the page as a user's browser would.
A significant revelation in the documentation concerns resource management. The WRS implements a 30-day caching system for JavaScript and CSS resources, independent of HTTP caching directives. This approach helps preserve the crawl budget, which represents the number of URLs Googlebot can and wants to crawl from a website.
The documentation addresses several technical considerations for website operators. Notably, resource management can significantly impact a site's crawl budget. The authors outline three key recommendations: minimizing necessary resources while maintaining user experience, careful use of cache-busting parameters, and strategic resource hosting decisions.
On December 6, 2024, Google updated the documentation with an important caveat regarding resource hosting. The update warns that serving resources from different hostnames can negatively impact page performance due to connection overhead. This strategy is not recommended for critical resources like JavaScript or CSS but might be beneficial for larger, non-critical elements such as videos or downloads.
For technical verification of crawling activities, the documentation points to server access logs as the primary source of information. These logs contain entries for every URL requested by both browsers and crawlers. Google maintains published IP ranges in their developer documentation to facilitate crawler identification.
The Search Console Crawl Stats report serves as a secondary verification tool, providing detailed breakdowns of resource types per crawler. This report offers insights into crawling patterns and resource consumption across different content types.
The documentation explicitly addresses the relationship between robots.txt and resource crawling. While robots.txt can control crawler access, blocking rendering-critical resources may impair Google's ability to process page content effectively, potentially affecting search rankings.
Technical professionals can monitor Googlebot's crawling behavior through raw access logs, which record every URL request from browsers and crawlers. Google maintains documentation of its IP ranges to facilitate identification of its crawlers in these logs.
The timing between crawling stages can vary significantly due to scheduling constraints and server load considerations. This variability affects how quickly content becomes available in search results and highlights the importance of efficient resource management.
For developers seeking to optimize their sites for Googlebot, the documentation emphasizes the importance of resource efficiency. This includes minimizing the number of required resources, implementing careful cache management, and considering the strategic placement of different resource types.
The technical community can engage in discussions about crawling and rendering through the Search Central community and LinkedIn platform, where Google's technical team maintains an active presence for addressing implementation questions and concerns.
This comprehensive documentation represents a significant step in transparency regarding Google's technical processes, providing developers and technical SEO professionals with detailed insights into how their content is processed for inclusion in search results.
Share this article
The link has been copied!