Google's absence from IndexNow raises questions about web indexing standards
New protocol divides search industry as leading engine maintains traditional crawling approach.

New protocol divides search industry as leading engine maintains traditional crawling approach.
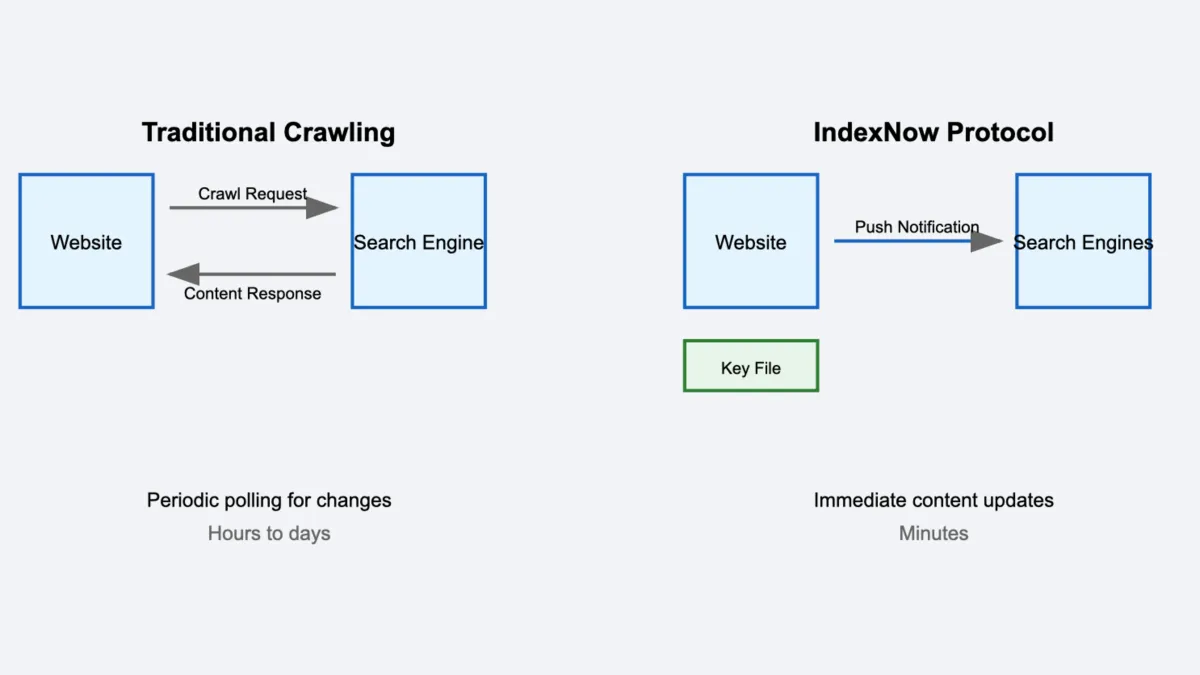
More than two years after Microsoft Bing and Yandex launched IndexNow, Google's continued absence from the protocol highlights fundamental differences in approaches to web content discovery and indexing.
The world's dominant search engine has maintained its traditional crawling infrastructure rather than adopting the push-based IndexNow system, which allows websites to instantly notify search engines of content changes. This decision reflects deeper technical and strategic considerations that shape how search engines discover and process web content.

Google's existing infrastructure represents massive investments in crawling technology. According to technical documentation from Google, its crawling system, powered by Googlebot, processes billions of pages daily through a sophisticated scheduling system that prioritizes pages based on multiple signals.
John Mueller, Search Advocate at Google, made a notable comment when IndexNow launched in October 2021, stating "we too, would like to be crawled less often." This seemingly light-hearted response underscores a fundamental question: whether reducing crawl frequency through push notifications aligns with search engines' broader data gathering needs.
Search engine crawling serves purposes beyond simple content discovery. According to search technology experts, the crawling process allows search engines to gather valuable data about website performance, link structures, and content relationships. These signals help determine page authority and relevance in search rankings.
By maintaining direct crawling control, Google can gather this supplementary data on its own schedule. The IndexNow protocol, while efficient for content updates, may not provide the same depth of technical information that direct crawling yields.
Google already offers limited API-based indexing solutions for specific content types. The Google Indexing API, restricted to job postings and live streaming content, suggests the company sees value in push-based indexing for time-sensitive content while maintaining traditional crawling for general web pages.
According to IndexNow's documentation, participating search engines must agree to share submitted URLs with all other participating engines. This requirement may present strategic concerns for search engines that view their indexing data as a competitive advantage.
The division between Google's approach and IndexNow creates complexity for website owners and content management systems. While platforms like Cloudflare have embraced IndexNow, offering one-click implementation for their customers, websites must still maintain separate processes for Google indexing.
According to data from Microsoft Bing, major websites including eBay, LinkedIn, and GitHub have adopted their URL submission API and plan to migrate to IndexNow. However, these sites must maintain parallel systems to ensure proper indexing across all search engines.
Google's decision to maintain independent crawling infrastructure may influence the broader adoption of IndexNow. As the search engine handling the majority of global search traffic, Google's participation would likely accelerate industry-wide standardization of push-based indexing.
The current situation creates a natural experiment in web indexing approaches. IndexNow promises reduced server load and faster content discovery, while traditional crawling provides search engines with richer contextual data. The effectiveness of these competing approaches may shape future standards for web content discovery.
Traditional web crawling requires significant computational resources from both search engines and websites. IndexNow's proponents argue that push-based notifications reduce unnecessary crawling of unchanged content, leading to more efficient resource utilization.
However, maintaining crawling infrastructure gives search engines direct control over data collection timing and depth. This control may outweigh potential resource savings, particularly for search engines with established crawling systems.
As IndexNow adoption grows among content delivery networks and content management systems, pressure may increase for standardization in content discovery protocols. The protocol's evolution and performance data from early adopters could influence future decisions about crawling infrastructure.
The distinction between push and pull-based indexing approaches highlights broader questions about web infrastructure efficiency and the balance between standardization and competitive advantage in search technology. As the web continues to grow, these technical and strategic considerations will shape how search engines discover and process content.