Google's new tiny AI model reads user intent before searches happen
Research from Google shows small multimodal models analyze smartphone screens to predict what users want before they type queries, shifting search behavior.

Research from Google shows small multimodal models analyze smartphone screens to predict what users want before they type queries, shifting search behavior.

Google today announced a technical breakthrough in intent understanding that could fundamentally alter how search engines anticipate user needs across 300 million Android devices. The company's research team published findings showing that multimodal AI models with fewer than 10 billion parameters can analyze sequences of mobile device interactions and accurately predict user goals without sending screen data to remote servers.
The research paper "Small Models, Big Results: Achieving Superior Intent Extraction Through Decomposition," presented at EMNLP 2025, introduces a two-stage workflow that processes user interface trajectories entirely on mobile devices. The models run locally on smartphones, analyzing what users see and do without transmitting screen content to Google's cloud infrastructure. This on-device architecture addresses privacy concerns while enabling sophisticated intent prediction capabilities.
"By decomposing trajectories into individual screen summaries, our small models achieve results comparable to large models at a fraction of the cost," stated the research team led by software engineers Danielle Cohen and Yoni Halpern in the announcement published on the Google Research blog. The technical advancement arrives as Google's AI Max features increasingly rely on inferred intent matching rather than explicit keyword targeting.
The privacy implementation differs significantly from cloud-based AI systems. While the models can "see" screen content, images, and user actions, this processing occurs within the device itself. The AI analyzes interface elements, text, and interaction patterns locally without creating copies that transmit to external servers. This architecture mirrors Google's approach to scam detection, where on-device machine learning models analyze content while maintaining end-to-end encryption.
Technical specifications reveal the models contain fewer than 10 billion parameters - small enough to fit in smartphone memory and execute using mobile processors. Large language models typically exceed 100 billion parameters and require datacenter infrastructure, making them impractical for real-time on-device processing. The size constraint represents both an engineering achievement and a privacy design decision.
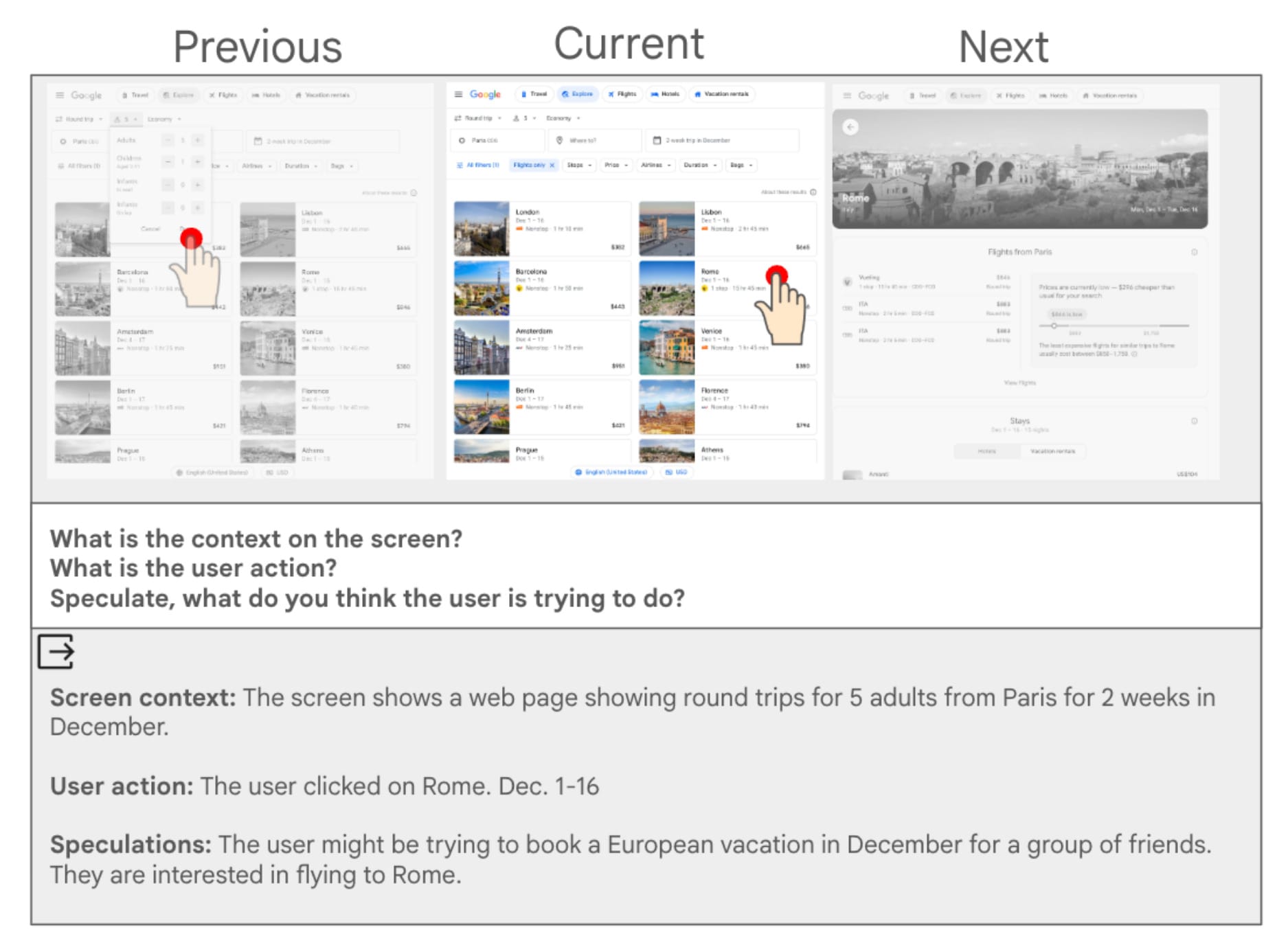
The system analyzes three consecutive screens - previous, current, and next - to understand context and user actions. For each interaction, the model generates summaries answering three questions: What is the relevant screen context? What did the user just do? What is the user trying to accomplish? This structured approach allows the model to build comprehensive understanding from fragmented interface elements and user gestures.
A practical example from the research demonstrates the system's capabilities. When a user views round-trip flight options from Paris to various European destinations for five adults traveling two weeks in December, then clicks on a Rome listing dated December 1-16, the system generates this analysis: "Screen context: The screen shows a web page showing round trips for 5 adults from Paris for 2 weeks in December. User action: The user clicked on Rome. Dec. 1-16. Speculations: The user might be trying to book a European vacation in December for a group of friends. They are interested in flying to Rome."
The decomposed workflow first processes each screen independently through a small multimodal language model. These individual summaries then feed into a fine-tuned model that extracts a single sentence describing the user's overall intent. The second stage model undergoes specific training techniques to avoid hallucination - generating information not present in the input data.
Label preparation methods remove any information from training data that doesn't appear in screen summaries. "Because the summaries may be missing information, if we train with the full intents, we inadvertently teach the model to fill in details that aren't present," the paper explains. This constraint forces the model to work only with observable data rather than inventing plausible details.
The system deliberately drops speculation during the second stage despite requesting it during initial screen analysis. The research found that asking models to speculate about user goals improves individual screen summaries but confuses the intent extraction process. "While this may seem counterintuitive - asking for speculations in the first stage only to drop them in the second - we find this helps improve performance," according to the methodology section.
Technical evaluation employs a Bi-Fact approach that decomposes both reference and predicted intents into atomic facts - details that cannot be broken down further. For instance, "a one-way flight" constitutes an atomic fact, while "a flight from London to Kigali" represents two atomic facts. The system counts how many reference facts appear in predicted intents and how many predicted facts the reference intent supports, calculating precision and recall metrics.
This granular evaluation methodology enables tracking how information flows through both processing stages. Propagation error analysis shows where the system loses accuracy. Of 4,280 ground truth facts in test data, 16% were missed during interaction summarization. Another 18% were lost during intent extraction. The precision analysis revealed that 20% of predicted facts came from incorrect or irrelevant information in interaction summaries that the extraction stage failed to filter.
The decomposed approach outperformed two natural baselines across all tested configurations. Chain-of-thought prompting and end-to-end fine-tuning both showed lower Bi-Fact F1 scores compared to the two-stage decomposition method. The advantage held true when researchers tested on both mobile device and web trajectories using Gemini and Qwen2 base models.
Most significantly, applying the decomposed method with Gemini 1.5 Flash 8B achieved comparable results to using Gemini 1.5 Pro - a model significantly larger. The Flash 8B model contains approximately 8 billion parameters while Pro exceeds 100 billion parameters, representing more than a 10x difference in model size. This performance parity at comparable computational cost demonstrates that architectural decisions and training methodologies can compensate for raw parameter count in specialized tasks.
The research builds on Google's ongoing work in user intent understanding, which has become increasingly important as the company develops assistive features for mobile devices. Google's broader keyword matching system already employs BERT (Bidirectional Encoder Representations from Transformers) to understand context beyond literal word matching. The current research extends this capability to visual interface elements and gestural interactions.
For mobile advertising platforms, the technology presents new opportunities and challenges. Traditional keyword targeting assumes users explicitly state their needs through search queries. Intent understanding from UI trajectories enables prediction before any query formulation occurs. A user browsing European vacation options might receive travel-related suggestions before typing "flights to Rome" into a search bar.
The distinction between explicit search intent and inferred behavioral intent has significant implications for attribution modeling. When AI Max features already match advertisements to inferred intent rather than typed queries, adding pre-query intent prediction creates additional complexity in determining which exposure influenced user decisions.
Google is getting ready for intent analysis on steroids!
— Pedro Dias (@pedrodias) January 22, 2026
For someone in SEO, this research signals a shift in how search engines and operating systems might understand user intent before a query is even typed. https://t.co/eSnbMBbyAZ
The on-device processing architecture addresses data sensitivity concerns that arise when AI systems analyze personal communications, financial transactions, or health information visible in mobile interfaces. The entire workflow executes locally - screen analysis, summary generation, and intent extraction all occur within device memory without creating server-accessible copies. This differs substantially from cloud-based AI assistants that transmit queries and context to remote systems for processing.
However, on-device processing does not eliminate all privacy considerations. The AI models installed on devices can analyze any screen content the device displays, including sensitive information. Users retain no technical mechanism to prevent the on-device model from "seeing" specific applications or content types while allowing analysis of others. The privacy protection stems from preventing transmission rather than limiting observation.
The research team identified several technical constraints governing model performance. Text content in screen summaries cannot exceed approximately 1,000 tokens per interaction. The system processes a maximum of 20 consecutive screens before truncating older interactions. These limits reflect practical memory constraints on mobile devices where multiple applications compete for limited computational resources.
The evaluation datasets came from publicly available automation datasets containing examples pairing user intents with action sequences. The research team did not collect new user data specifically for this project, instead relying on existing datasets that document how people interact with web browsers and mobile applications to accomplish specific goals.
Model performance varied based on task complexity. Simple transactional intents like "book a flight to London" achieved higher accuracy than complex research tasks like "compare European vacation destinations for a December group trip within a $5,000 budget." The system struggled most with ambiguous interactions where user intent remained unclear even when examining multiple consecutive screens.
The research acknowledges fundamental challenges in trajectory summarization. Human evaluators sometimes disagree about user intent when examining identical screen sequences, suggesting the task contains inherent ambiguity. A user viewing concert listings might be researching entertainment options, planning a specific outing, or simply browsing without purchase intent. Distinguishing these scenarios requires additional context not always visible in interface elements.
Future development directions include expanding the system's capability to handle longer interaction sequences and improving accuracy on complex multi-step tasks. The team expressed interest in applying these techniques to other interface understanding problems beyond intent extraction, such as automated user interface testing and accessibility assistance.
The timing of this research coincides with broader industry adoption of small language models for specialized tasks. NVIDIA published research in August 2025 showing that models with fewer than 10 billion parameters can effectively handle 60-80% of AI agent tasks currently assigned to models exceeding 70 billion parameters, suggesting parameter efficiency has become a critical focus across major AI research organizations.
Google's implementation strategy emphasizes gradual deployment. The research paper represents foundational work rather than immediate product launch. "Ultimately, as models improve in performance and mobile devices acquire more processing power, we hope that on-device intent understanding can become a building block for many assistive features on mobile devices going forward," according to the conclusion section.
The research team included Danielle Cohen and Yoni Halpern as software engineers, along with coauthors Noam Kahlon, Joel Oren, Omri Berkovitch, Sapir Caduri, Ido Dagan, and Anatoly Efros. The paper received presentation at EMNLP 2025, an academic conference focused on empirical methods in natural language processing.
For search marketing professionals, these developments signal potential shifts in how search engines understand and respond to user needs. The distinction between query-based and behavior-based intent understanding creates new optimization considerations. Content that ranks well for explicit search queries may not surface in contexts where systems predict intent from interface interactions alone.
The research also highlights tensions between helpful personalization and user privacy. Systems that accurately predict user needs before explicit requests require analyzing on-screen information continuously. Google's emphasis on on-device processing addresses transmission privacy concerns but doesn't eliminate questions about the extent to which AI systems should monitor user behavior to improve service quality.
Mobile operating system integration represents another strategic consideration. As AI Mode features spread across Android devices, operating system vendors gain unprecedented visibility into user interactions across all installed applications. The research's small model approach enables this capability while maintaining reasonable battery life and processing speeds.
The technical achievement demonstrates that multimodal understanding - processing both visual interface elements and textual content simultaneously - no longer requires massive computational resources. This democratization of multimodal AI capabilities may accelerate development of competing systems from other technology companies seeking similar intent understanding features for their mobile platforms.
Industry observers have noted Google's aggressive AI integration strategy across its product portfolio. Search executives have described AI as "the most profound" transformation in the company's history, surpassing even the mobile computing transition. Intent understanding from UI trajectories represents one component of this broader transformation toward predictive, assistive computing experiences.
The research paper makes no claims about commercial deployment timelines or integration with existing Google products. The announcement emphasizes scientific contribution and methodological innovation rather than product features. This positioning suggests Google maintains separation between research exploration and product development decisions, though published research often indicates future product directions.
Who: Google Research team including software engineers Danielle Cohen and Yoni Halpern, along with coauthors Noam Kahlon, Joel Oren, Omri Berkovitch, Sapir Caduri, Ido Dagan, and Anatoly Efros announced the research affecting users of 300 million Android devices.
What: Google developed a two-stage decomposed workflow using small multimodal language models (fewer than 10 billion parameters) to understand user intent from mobile device interaction sequences. The system operates entirely on-device, analyzing screens locally without transmitting content to servers, then extracting overall intent from generated summaries while achieving performance comparable to models 10 times larger.
When: The announcement was made on January 22, 2026, with the research paper presented at EMNLP 2025. The work builds on previous intent understanding research from Google's team.
Where: The technology operates entirely on-device across Android mobile platforms. Processing occurs locally within smartphone memory using device processors, with no screen content transmitted to Google's cloud infrastructure. The research methodology was tested on both mobile device and web browser trajectories using publicly available automation datasets.
Why: Google aims to enable AI agents that anticipate user needs before queries are typed, supporting assistive features on mobile devices. The on-device processing architecture maintains privacy by preventing transmission of screen content to remote servers while enabling sophisticated intent prediction. The research demonstrates that architectural innovations can achieve performance comparable to large models at a fraction of computational cost, making advanced AI features practical for battery-powered mobile devices without requiring constant server connectivity.