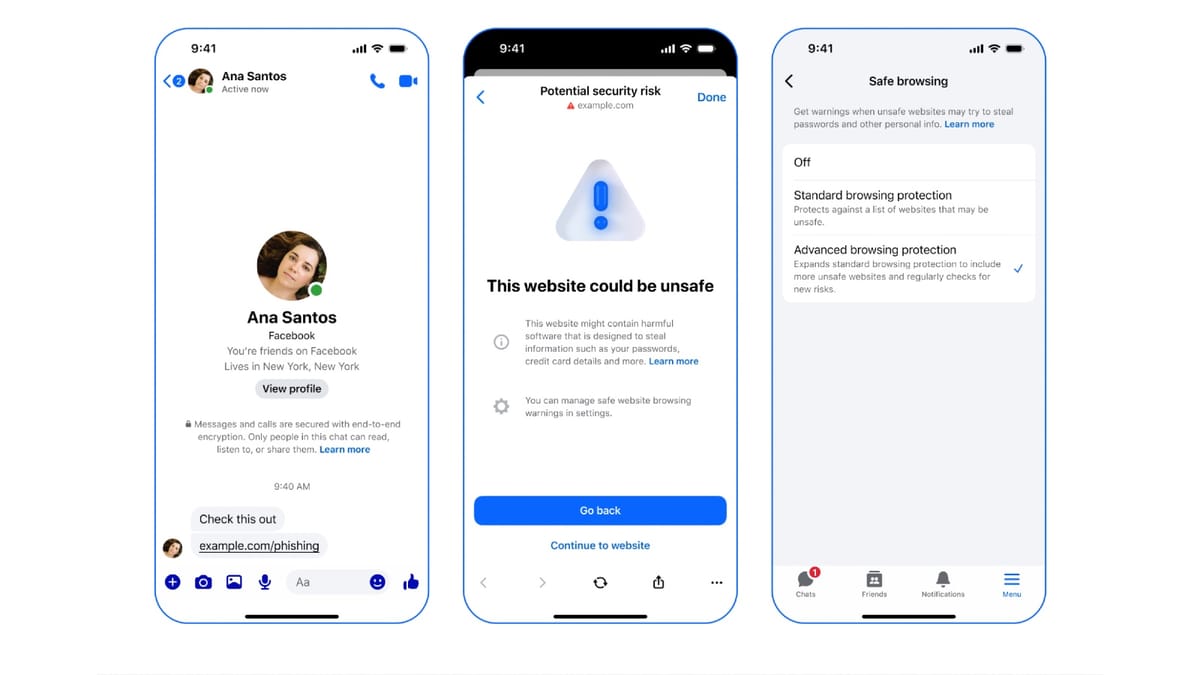
Meta yesterday published a detailed technical account of how Advanced Browsing Protection (ABP) works inside Messenger - a feature that checks links clicked within end-to-end encrypted chats against a database of millions of potentially malicious websites, all without the company's servers ever seeing the plaintext URL a user tapped on.
The post, written by engineers Emma Connor, Artem Ignatyev, and Kevin Lewi and published to the Engineering at Meta blog on March 9, 2026, is notable less for announcing something new than for opening up the underlying engineering. Rarely do platform operators explain, in public, how they reconcile the competing demands of security scanning and user privacy. What follows is technically dense - and worth unpacking for anyone who works on platforms where Messenger is a customer acquisition or support channel.
The problem: scanning links inside encrypted messages
End-to-end encryption (E2EE) on Messenger means that direct messages and calls are protected from anyone in transit, including Meta itself. That is the point. But it creates an immediate operational problem: if a user receives a malicious link inside an encrypted chat - perhaps from a compromised contact - how does the platform warn them without reading the message?
Messenger's answer has two layers. The first, called Safe Browsing, uses on-device models to analyze potentially malicious links without involving the server at all. The second and more sophisticated layer is ABP, which taps into "a continually updated watchlist of millions more potentially malicious websites," according to the engineering post. The challenge is doing that server-side lookup while keeping the queried URL private.
That tension - between a comprehensive server-side blocklist and user privacy - is what the ABP system is designed to resolve. Meta's engineers spent considerable effort describing exactly how.
The cryptographic concept at the core of ABP is private information retrieval (PIR). In the classical PIR setting, a client queries a server holding a database to determine whether the subject of its query appears in that database - and the server learns, ideally, nothing about what was queried. A theoretically trivial solution exists: the server simply sends the entire database to the client, which can then search locally. In practice, Meta's blocklist is too large and too frequently updated to transfer in full. Revealing the entire database to users would also, according to the post, "inadvertently aid attackers attempting to circumvent the system."
The approach Meta adopted instead builds on existing work that uses an oblivious pseudorandom function (OPRF) combined with database sharding - dividing entries into buckets so that the lookup operation operates over a fraction of the full database rather than its entirety. But that starting point came with two problems specific to URL matching.
First, an OPRF works cleanly when queries are exact matches. URL lookups are not exact: an entry for "example.com" in the blocklist should flag "example.com/a/b/index.html" as a match even though the strings differ. Second, the client must still tell the server which bucket to search, which introduces an inherent privacy tradeoff. Smaller buckets mean faster lookups but more information leaked. Larger buckets mean less information leaked but slower responses.
URL prefix queries and the bucket-balancing problem
To handle prefix matching, Meta considered running parallel PIR queries - one for each path segment of a URL. For a link like "example.com/a/b/index.html," the client would query four separate paths: the domain alone, then with one segment, then two, then the full path. Functionally this works, but privacy-wise it multiplies the information leakage. According to the post, if the server learns B bits per query and a URL has P path prefixes, the server ends up learning P times B bits total - potentially enough to identify a link uniquely for very long URLs.
The engineers' solution was to have the server group blocklist entries by domain rather than by full URL before bucketing. The client then queries only the bucket corresponding to the URL's domain and checks all path prefix components within that single bucket. Information leakage drops back to B bits. But this creates a new imbalance problem. When hashing full URLs across buckets, entries distribute roughly uniformly because each is mapped pseudorandomly. When hashing only by domain, entries cluster heavily. URL shortening services were the cited example: they host enormous numbers of links - both benign and malicious - all sharing the same root domain. A single domain can therefore dominate a bucket, inflating its size and driving up the padding overhead that every bucket must carry to prevent size from revealing content.
Pre-processing rulesets: iterative bucket balancing
The mechanism Meta devised to address that imbalance is a pre-processing ruleset - a set of operations the server computes ahead of time and shares with clients so that both sides apply identical hashing logic at lookup time.
Each ruleset maps an 8-byte hash prefix to a number of URL path segments to append before hashing. When the client computes the bucket identifier for a link, it starts by hashing the domain, checks whether that hash matches a ruleset entry, and if it does, recomputes the hash after appending the specified number of path segments. The process repeats until no ruleset match is found, at which point the first two bytes of the final hash prefix serve as the bucket identifier.
The server generates the ruleset iteratively: start with domain-only hashing, identify the largest bucket, find the most common domain in it, and add a rule breaking up that domain by appending additional path segments. This continues until all buckets fall below an acceptable size threshold. The invariant - that any blocked URL will hash into the bucket containing its corresponding blocklist entry - holds as long as the blocklist contains no redundant entries and the hash function produces no collisions among those entries.
At lookup time, the client sends the bucket identifier together with OPRF-blinded elements for each path segment of the queried URL, padded to a fixed maximum to prevent the number of segments from leaking information about the link. The server responds with bucket contents and OPRF responses, encrypted under the client's public key. The client unblinds the OPRF output and checks for a match. A match triggers a warning.
Three layers of query protection
The bucket identifier itself still represents information about the user's link. Meta layered three separate mechanisms on top of the OPRF scheme to constrain what a hypothetically adversarial server could learn from it.
Confidential Computing via AMD SEV-SNP. To prevent the hash prefix from being exposed to Meta's infrastructure, the server-side lookup runs inside a confidential virtual machine (CVM) backed by AMD's SEV-SNP technology. The CVM generates an attestation report containing a container manifest with hash digests of the launch configuration and packages, a public key generated at startup whose corresponding private key remains within the trusted execution environment (TEE), a certificate chain rooted in AMD's Key Distribution Service, and a transparency log witness signature that prevents the server from presenting different attestation reports to different clients.
The client verifies all certificates and signatures, then uses the embedded public key to establish an encrypted channel directly to the CVM. Only the CVM can decrypt the incoming bucket identifier. Meta noted in the post that it used a similar AMD SEV-SNP setup for WhatsApp Private Processing, published last year, and that the hardware setup details are broadly comparable between the two systems.
One gap the engineers acknowledged openly: external security researchers currently cannot independently verify the artifacts. "We aim to provide a platform for hosting these artifacts in the near future," the post states.
Oblivious RAM. AMD SEV-SNP encrypts memory pages but does not hide the pattern of memory accesses from an attacker with administrative host privileges who monitors access patterns over time. To close that gap, Meta employs Oblivious RAM (ORAM) - specifically an algorithm called Path ORAM. Even if the attacker can observe which memory locations are read, ORAM ensures those access patterns reveal nothing about which bucket was actually retrieved.
For databases of moderate size, Meta also uses a simpler technique: loading multiple copies of the database into memory simultaneously and scanning all B buckets on every request, not just the one the client queried. The B-1 superfluous accesses are computationally wasteful but prevent the access pattern itself from leaking the bucket index. Path ORAM reduces this overhead asymptotically - from linear to sublinear - for larger databases. Meta has open-sourced its Path ORAM library.
Oblivious HTTP. The third layer involves a third-party proxy operating the Oblivious HTTP (OHTTP) protocol. The proxy sits between the client and the server, strips identifying information including the client's IP address from incoming requests, and forwards de-identified payloads to the CVM. The server decrypts the request payload but cannot correlate it to a specific user. The combination of OHTTP and the CVM's encrypted channel means that neither the proxy nor Meta's servers ever simultaneously hold both the user's identity and the URL they queried.
The full request lifecycle
The complete ABP workflow, as described in the post, separates into a background phase and a per-click phase.
In the background phase, the server periodically pulls updated URL database entries, computes the ruleset and buckets, loads the database into the TEE using ORAM, generates a keypair, produces an attestation report via AMD SEV-SNP hardware, and makes the attestation report and ruleset available to clients through the third-party proxy.
When a user clicks a link inside an E2EE Messenger chat, the following sequence occurs: the client applies the ruleset to compute the bucket identifier; encrypts it for the specific CVM instance using its public key; computes OPRF requests for each path segment, padded to a fixed maximum; sends the encrypted bucket identifier and OPRF requests through the third-party proxy to the server along with a client public key; the server evaluates the OPRF requests and uses ORAM to retrieve the relevant bucket; returns the OPRF responses and bucket contents encrypted under the client's key; and the client decrypts, completes the OPRF evaluation, and checks for a match. If a match is found, the client displays a warning about the link.
The entire process is designed so that the server learns, at most, which bucket was accessed - not which URL was queried.
Why this matters for the marketing and advertising community
For marketing professionals, Messenger occupies a growing and contested position. Meta's utility messages for Messenger launched in July 2025 as a mechanism for businesses to send order updates, appointment reminders, and account alerts through pre-approved templates. Enhanced marketing messages on Messenger launched the same month, allowing businesses in 21 countries to send personalized promotional campaigns to opted-in subscribers. Messenger has, in other words, become a business communication channel - which means it is also a vector for phishing and social engineering attacks targeting users who trust it as a customer service interface.
The ABP system matters in this context for two reasons. First, it illustrates the technical approach Meta is taking to user safety within encrypted messaging at a moment when that architecture is under sustained legal scrutiny. A San Francisco court on March 3, 2026, signed a $50 million final judgment against Meta tied to Facebook user data shared with third-party developers, part of a pattern of enforcement connecting data handling practices to legal exposure. Meta also submitted its third annual Digital Markets Act compliance report to the European Commission on March 6, 2026, covering advertising and data infrastructure across all five designated core platform services.
Second, the architecture described in the ABP post represents a genuine attempt to satisfy competing regulatory requirements that affect the entire advertising ecosystem. Privacy regulators generally push platforms to collect less data and limit server-side processing. Security regulators and user safety advocates push platforms to detect and block harmful content more aggressively. ABP attempts to satisfy both by moving the security enforcement logic to a hardware-attested enclave and routing client queries through an anonymising proxy - an approach that has parallels in how clean room technology is applied to advertising measurement.
WhatsApp's broader privacy architecture has been contested at the European level for years, with the Advocate General siding with WhatsApp in a landmark case over whether EDPB binding decisions can be directly challenged in EU courts. The CJEU Grand Chamber eventually ruled on February 10, 2026 that such decisions are open to challenge. Against that backdrop, the publication of detailed technical documentation about ABP reads partly as transparency and partly as a record - a publicly verifiable account of what the system actually does.
Open questions and limitations
The engineers were candid about what ABP does not yet achieve. The transparency mechanism - the attestation reports that allow clients to verify the code running in the CVM - is not yet open to external audit. The artifacts are not publicly hosted. Until they are, independent verification of the system's claimed properties is limited.
The post also acknowledged that lattice-based cryptographic constructions could improve the privacy-efficiency tradeoff beyond what sharding currently allows, but described these as not yet practical enough at Meta's scale. That note suggests the current architecture represents an engineering compromise rather than a theoretical ceiling - and that future versions of ABP may look substantially different as post-quantum cryptography matures.
Finally, the post is silent on how frequently the URL blocklist is updated, how large it currently is beyond "millions" of potentially malicious websites, and what false positive or false negative rates look like in practice. Those operational metrics would be relevant to anyone assessing the system's reliability as a safety control within business messaging workflows.
Timeline
- December 6, 2023 - Meta publishes foundational post on building end-to-end security for Messenger
- November 20, 2025 - Key Transparency comes to Messenger, a related security infrastructure development
- July 1, 2025 - Meta launches enhanced marketing messages on Messenger for promotional campaigns in 21 countries
- July 29, 2025 - Meta announces utility messages on Messenger in open beta for order updates and reminders
- November 15, 2025 - WhatsApp enables third-party messaging in Europe under DMA compliance
- November 20, 2025 - Meta agrees to $190 million shareholder settlement over Cambridge Analytica-era privacy failures
- February 9, 2026 - EU pushes Meta toward interim measures over WhatsApp AI lockout, European Commission sends Statement of Objections
- February 10, 2026 - CJEU Grand Chamber rules EDPB binding decisions are directly challengeable, following the Advocate General's earlier opinion siding with WhatsApp
- March 3, 2026 - San Francisco court signs $50 million Meta privacy injunction over Facebook data controls
- March 6, 2026 - Meta submits third annual DMA compliance report to the European Commission
- March 9, 2026 - Meta publishes technical deep-dive on Advanced Browsing Protection in Messenger, authored by Emma Connor, Artem Ignatyev, and Kevin Lewi
Summary
Who: Meta engineers Emma Connor, Artem Ignatyev, and Kevin Lewi, writing for the Engineering at Meta blog on behalf of Messenger's security and privacy teams.
What: A detailed technical disclosure of how Advanced Browsing Protection (ABP) in Messenger detects malicious links within end-to-end encrypted chats using a layered system of private information retrieval, pre-processing rulesets, AMD SEV-SNP confidential computing, Oblivious RAM via Path ORAM, and Oblivious HTTP routing - all designed so that Meta's servers cannot learn the plaintext URL a user queried.
When: The post was published on March 9, 2026. The ABP feature itself predates this publication; the post is a technical disclosure rather than a product launch announcement.
Where: The technical infrastructure runs on Meta's server-side systems, with the security-sensitive lookup logic operating inside a confidential virtual machine backed by AMD's SEV-SNP hardware. Client-side components run within the Messenger application on users' devices. The OHTTP proxy operates as a third-party intermediary between clients and the CVM.
Why: Messenger's end-to-end encryption prevents Meta from reading message content, but that same property prevents server-side scanning for malicious links. ABP resolves this tension by combining cryptographic protocols with hardware-attested enclaves to enable security checks without exposing user query data. The publication of technical details serves transparency goals at a moment when Meta faces sustained regulatory and legal scrutiny over its data handling practices across multiple jurisdictions.
Share this article
The link has been copied!