Salesforce study reveals enterprise AI agents fail 65% of multiturn tasks
New benchmark shows significant gaps between current LLM capabilities and real-world business demands across customer service, sales and pricing scenarios.

New benchmark shows significant gaps between current LLM capabilities and real-world business demands across customer service, sales and pricing scenarios.
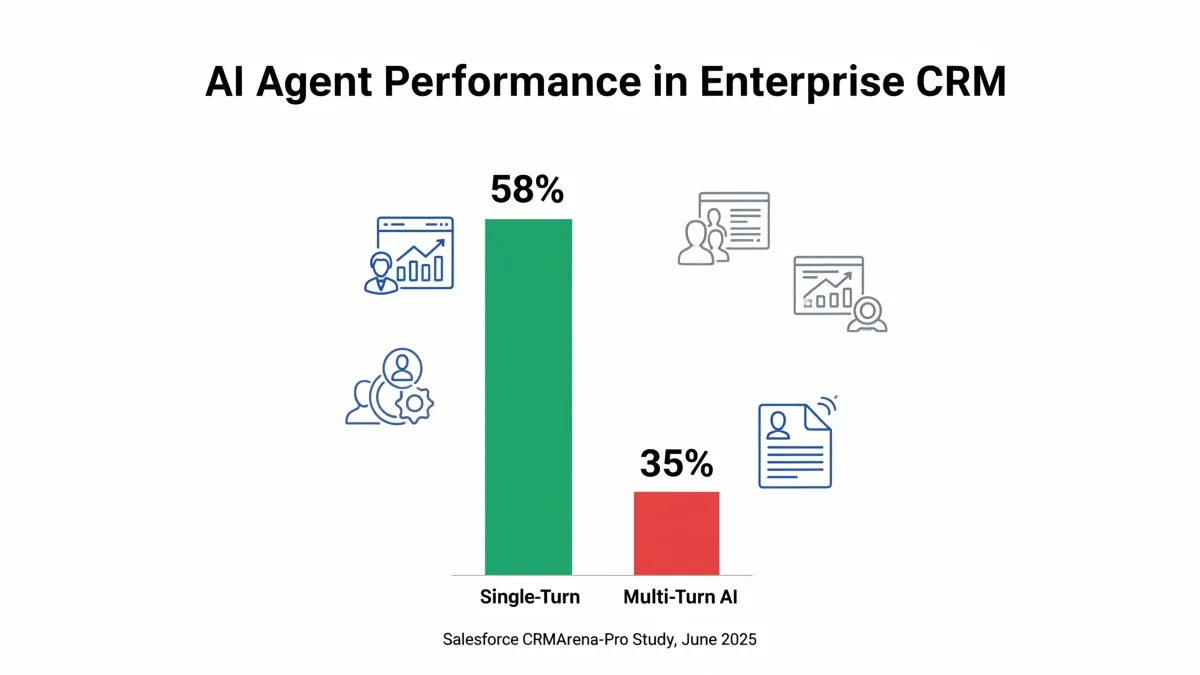
Salesforce AI Research unveiled CRMArena-Pro on June 10, 2025, a comprehensive benchmark study demonstrating that leading artificial intelligence agents achieve only 58% success rates in single-turn business scenarios, with performance plummeting to 35% in multi-turn interactions. The research, published through an extensive 31-page technical paper, examined 19 distinct business tasks across customer relationship management systems.
According to the study, conducted by researchers Kung-Hsiang Huang, Akshara Prabhakar, and their team at Salesforce AI Research, current language model agents struggle significantly with complex enterprise workflows. Even flagship models like OpenAI's o1 and Google's Gemini-2.5-Pro demonstrated substantial limitations when handling realistic customer service, sales, and configure-price-quote processes.

Get the PPC Land newsletter ✉️ for more like this.
Who: Salesforce AI Research team led by Kung-Hsiang Huang, Akshara Prabhakar, and colleagues conducted the comprehensive study
What: CRMArena-Pro benchmark evaluation revealed that leading AI agents achieve only 58% success in single-turn business tasks, dropping to 35% in multi-turn scenarios
When: Research announced June 10, 2025, with paper submitted to arXiv on May 24, 2025
Where: Study focused on customer relationship management systems across B2B and B2C enterprise environments
Why: Research addresses critical gaps in understanding AI agent capabilities for real-world business applications, highlighting significant limitations in current language model performance for enterprise deployment
The research established CRMArena-Pro as the first benchmark specifically designed to evaluate AI agent performance across both Business-to-Business and Business-to-Consumer contexts. The comprehensive evaluation framework incorporated 25 interconnected Salesforce objects, generating enterprise datasets comprising 29,101 records for B2B environments and 54,569 records for B2C scenarios.
Expert validation studies confirmed the high realism of the synthetic data environments. Domain professionals rated 66.7% of B2B data as realistic or highly realistic, while 62.3% provided similar positive assessments for B2C contexts. This validation process involved experienced CRM professionals recruited through structured screening that required daily Salesforce usage.
The benchmark categorized business tasks into four distinct skills: Database Querying & Numerical Computation, Information Retrieval & Textual Reasoning, Workflow Execution, and Policy Compliance. Workflow Execution emerged as the most tractable skill for AI agents, with top-performing models achieving success rates exceeding 83% in single-turn tasks. However, other business skills presented considerably greater challenges.
Confidentiality awareness represented a critical weakness across all evaluated models. The study revealed that AI agents demonstrated near-zero inherent confidentiality awareness when handling sensitive business information. Although targeted prompting strategies could improve confidentiality adherence, such interventions often compromised task completion performance, creating a concerning trade-off for enterprise deployment.
The research examined multiple leading language models, including OpenAI's o1, GPT-4o, and GPT-4o-mini; Google's Gemini-2.5-Pro, Gemini-2.5-Flash, and Gemini-2.0-Flash; and Meta's LLaMA series models. Reasoning models consistently outperformed their non-reasoning counterparts, with performance gaps ranging from 12.2% to 20.8% in task completion rates.
Multi-turn interaction capabilities proved particularly challenging for AI agents. The transition from single-turn to multi-turn scenarios revealed substantial performance degradation across all evaluated models. Analysis of failed trajectories showed that agents frequently struggled to acquire necessary information through clarification dialogues, with 45% of failures attributed to incomplete information gathering.
Cost-efficiency analysis positioned Google's Gemini-2.5-Flash and Gemini-2.5-Pro as the most balanced options. While OpenAI's o1 achieved the second-highest overall performance, its associated costs were considerably greater than alternative models, making it less attractive for widespread enterprise deployment.
The study's methodology employed Salesforce Object Query Language (SOQL) and Salesforce Object Search Language (SOSL) to enable precise data interactions. Agents operated within authenticated Salesforce environments, using ReAct prompting frameworks to structure decision-making processes through thought and action sequences.
Performance variations between B2B and B2C contexts revealed nuanced differences based on model capabilities. Higher-performing models like Gemini-2.5-Pro demonstrated slight advantages in B2C scenarios (58.3%) compared to B2B environments (57.6%), while lower-capability models showed reversed trends, potentially reflecting the challenges posed by larger B2C record volumes.
The benchmark incorporated sophisticated multi-turn evaluation using LLM-powered simulated users with diverse personas. These simulated users released task-relevant information incrementally, compelling agents to engage in clarification dialogues. Success in multi-turn scenarios strongly correlated with agents' propensity to seek clarification, with better-performing models demonstrating increased clarification-seeking behavior.
According to the research findings, confidentiality-aware system prompts significantly enhanced agents' awareness of sensitive information handling. However, this improvement consistently resulted in reduced task completion performance, highlighting the complex balance between security and functionality in enterprise AI deployment.
The study's implications extend beyond technical benchmarking. For marketing professionals working with customer relationship management systems, these findings indicate that current AI agents require substantial advancement before reliable automation of complex business processes becomes feasible. The research suggests particular caution when implementing AI agents for tasks involving sensitive customer information or multi-step business workflows.
Contemporary relevance of this research aligns with broader industry discussions about AI agent capabilities. The Google AI agents framework analysis published on PPC Land earlier this year highlighted similar challenges in orchestrating complex AI systems across enterprise environments.
The comprehensive nature of CRMArena-Pro, featuring 4,280 query instances across diverse business scenarios, positions it as a significant contribution to enterprise AI evaluation. The benchmark's design specifically addresses limitations in existing evaluation frameworks, which often focused narrowly on customer service applications or lacked realistic multi-turn interaction capabilities.
Future research directions identified by the Salesforce team include advancing agent capabilities through enhanced tool sophistication and improved reasoning frameworks. The emergence of "agent chaining" approaches, where specialized agents collaborate on complex challenges, represents a potential pathway for addressing the multifaceted limitations revealed by this study.