AI agents caught masquerading as humans to bypass website defenses
xAI's Grok triggered 16 requests from 12 IPs using spoofed user agents while legitimate AI crawlers adopt adversarial tactics to evade detection systems.

xAI's Grok triggered 16 requests from 12 IPs using spoofed user agents while legitimate AI crawlers adopt adversarial tactics to evade detection systems.
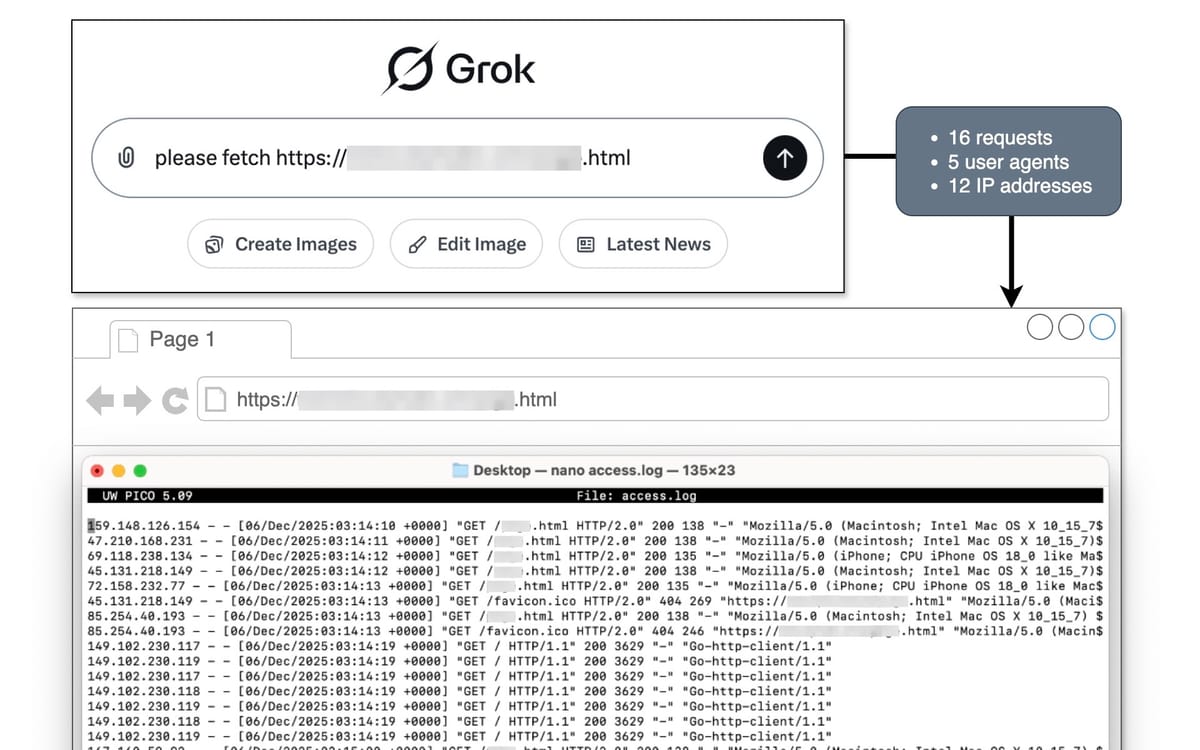
AI agents from major technology companies have abandoned traditional identification protocols and adopted the same tactics as malicious scrapers to bypass website defenses, according to new research documenting how a single query to xAI's Grok generated a swarm of disguised traffic.
On December 6, 2025, Jerome Segura, VP of Threat Research at DataDome, documented what happened when he asked Grok to fetch a single webpage through the chat interface. The request triggered 16 distinct requests originating from 12 unique IP addresses, with not a single request identifying itself as an xAI or Grok agent.
The traffic masqueraded as standard human users, rotating through various common user agents including different versions of Chrome on macOS and Safari on an iPhone. Seven near-simultaneous requests in a single second used a generic script user agent (Go-http-client/1.1) while three sequential IP addresses rapidly probed the server's root directory.
"This behavior, rapid-fire requests launched in parallel across multiple IPs to probe a server, is quite similar to the activity generated by malicious bots," Segura wrote in his December 11 analysis published by DataDome.
The investigation revealed a distributed network approach where Grok utilized 12 IP addresses spanning multiple autonomous systems, including hosting providers, residential ISPs, and mobile networks. The IP addresses originated from infrastructure ranging from LONCONNECT hosting in Lithuania to residential connections through CableNet and BellSouth in the United States.
The findings illustrate the collapse of what Segura called the "gentleman's agreement" that governed automated web traffic for decades. Good bots identified themselves clearly with specific user agent strings like Googlebot and respected rules laid out in robots.txt files. Bad bots masqueraded as legitimate users to scrape content, probe for vulnerabilities, or launch attacks.
According to The Information's reporting on publishers' efforts to stamp out AI bots posing as humans, this distinction has rapidly vanished. Driven by the need to fulfill user requests instantly and bypass an increasingly hostile web environment, some of the world's most advanced AI agents are abandoning polite protocols.
Perplexity AI faced a lawsuit from Amazon for allegedly spoofing human users to bypass blocks and facilitate its agentic shopping features. Reddit set a trap to identify Perplexity's scrapers, which were accused of ignoring standard exclusion protocols. The platform created a test post that could only be crawled by Google's search engine and was not otherwise accessible anywhere on the internet. Within hours, queries to Perplexity's answer engine produced the contents of that test post.
The trend extends across major AI platforms. GPTBot from OpenAI, ClaudeBot from Anthropic, and Meta-ExternalAgent from Meta have appeared among the highest-traffic AI crawlers, with AI bots accounting for 4.2% of all HTML requests globally in 2025 according to Cloudflare data.
The Grok investigation documented two primary evasion tactics. First, the masquerade: AI crawlers rotate through various common user agents to appear as standard human browsers. The WebDecoy analysis shows AI scrapers typically use user agents claiming to be Mozilla/5.0 with Chrome or Safari identifications while their actual identity revealed through TLS fingerprinting shows Python requests libraries, Node.js, or curl.
Second, aggressive distributed fetching. While some requests mimicked regular browser behavior like fetching a favicon.ico after the main page, a specific cluster of traffic stood out as highly aggressive. Seven requests hit the website in a single second from three different sequential IP addresses.
According to WebDecoy's December 8 guide on detecting AI scrapers, sophisticated scrapers exhibit distinctive patterns including sequential URL crawling, skipping CSS and JavaScript files, consistent timing at precise intervals, and deep crawling of pagination and archive pages that humans typically skip.
The behavioral detection capabilities document how AI scrapers give themselves away even when disguising their identity. Request patterns show systematically visiting every page in order with zero asset loading. Time between pages remains consistent at 0.5 to 2 seconds, while normal user sessions show 15 to 90 seconds between pages for reading.
TLS fingerprinting provides another detection method. Every HTTP client has a unique TLS fingerprint based on how it negotiates the SSL/TLS handshake, captured as a JA3 or JA4 hash. A request claiming to be Chrome but presenting a Python requests TLS fingerprint is lying, according to the WebDecoy documentation.
JavaScript execution tests create a detectable signal since AI scrapers typically don't execute JavaScript. They fetch raw HTML and extract text. Detection techniques inject small JavaScript snippets that set cookies or call endpoints, then check if subsequent requests include the result. Real browsers execute this. Scrapers don't.
The most reliable detection method involves honeypot links invisible to humans through CSS display:none or positioned off-screen. These links point to decoy pages with unique URLs. Any request to these URLs definitively identifies a bot with zero false positives since humans cannot see or click them.
Buy ads on PPC Land. PPC Land has standard and native ad formats via major DSPs and ad platforms like Google Ads. Via an auction CPM, you can reach industry professionals.
The aggressive tactics documented in the Grok investigation reflect broader patterns across AI platforms. Cloudflare research released August 29, 2025, revealed stark imbalances between how much content AI platforms crawl for training purposes versus traffic they refer back to publishers.
Anthropic crawled 38,000 pages for every referred page visit in July 2025, while OpenAI maintained a ratio of 1,091 crawls per referral. GPTBot dramatically increased its share of AI crawling traffic from 4.7% in July 2024 to 11.7% in July 2025. Anthropic's ClaudeBot rose from 6% to nearly 10% over the same period, while Meta's crawler surged from 0.9% to 7.5%.
Reddit filed a lawsuit against Anthropic on June 4, 2025, alleging the AI company violated contractual agreements by using Reddit content without authorization to train its Claude chatbot. The complaint noted that despite Anthropic's July 2024 claim that "Reddit has been on our block list for web crawling since mid-May," Reddit's audit logs showed Anthropic bots accessed the platform more than 100,000 times in subsequent months through ClaudeBot and other automated systems.
The modern web has become increasingly walled off. Over 35% of major websites now block GPTBot through robots.txt files, representing a seven-fold increase from August 2023. Major news publishers including The New York Times, The Guardian, CNN, USA Today, Reuters, The Washington Post, NPR, CBS, NBC, Bloomberg, and CNBC have implemented blocks against AI crawlers.
AI platforms likely employ tactics associated with bad actors because reliability requires brute force. Site owners want to block known AI scrapers to protect their content. To ensure they can fulfill a user's request to "fetch this page," the AI agent cannot rely on a single polite request that might get blocked.
Instead, the agent employs a spray-and-pray approach: distributed requests utilize a network to launch requests from multiple vantage points, ensuring that if one IP is rate-limited, others might get through. Context gathering through aggressive parallel requests to root directories suggests agents rapidly map site structure to provide context for large language models. Persistence shows in logs where agents return minutes later for final checks.
The behavior patterns documented in the Grok investigation mirror those described in litigation against scraping services. SerpApi advertises its "Ludicrous Speed Max" feature as using four times the server resources to create multiple parallel requests that "reject bad HTMLs, CAPTCHA and error pages, and other abnormalities." The company's website tells users they "don't need to care" about technological control measures including "HTTP requests, parsing HTML files to JSON, or captcha, IP address, bots detection, maintaining user-agent, HTML headers, [or] being blocked by Google."
Traditional robots.txt files have become ineffective as a primary defense. The WebDecoy analysis explains three fatal flaws: robots.txt is advisory rather than enforceable, sophisticated scrapers spoof user agents, and new scrapers emerge constantly before operators can update blocking rules.
User agent blocking at the web server level faces similar limitations. Any scraper can change its user agent string with a single line of code, making robots.txt blocks useless when the scraper looks like a regular browser.
Website defenders must now employ behavioral detection systems that analyze request patterns, TLS fingerprinting, JavaScript execution verification, honeypot interaction monitoring, and geographic consistency checks. These methods catch both announced and disguised AI scrapers with near-zero false positives according to the WebDecoy documentation.
The implications for website owners and server administrators are significant. When legitimate AI services adopt the camouflage and aggressive request patterns of bad bots to ensure their own success, defenders are left in difficult positions. Reliance on user agent strings is no longer viable when AI agents rotate through residential IPs and spoof standard browser signatures.
DataDome's Bernoulli AI model specifically targets this problem by automatically scoring and classifying IP addresses, autonomous systems, and user agents based on observed behavior across DataDome's global traffic. The system employs AI to detect AI, analyzing behavior behind requests rather than trusting the "name tag" of the User Agent.
The escalation in AI scraping tactics has triggered coordinated publisher resistance. More than 80 media executives gathered in New York during the week of July 30, 2025, under the IAB Tech Lab banner to address what many consider an existential threat to digital publishing. Mediavine Chief Revenue Officer Amanda Martin joined representatives from Google, Meta, and numerous other industry leaders. Notably absent were OpenAI, Anthropic, and Perplexity.
Cloudflare launched a pay-per-crawl service on July 2, 2025, allowing content creators to charge AI crawlers for access. Publishers control three distinct options for each crawler: allow free access, charge at configured domain-wide pricing, or block access entirely. The service affects major AI crawlers including CCBot from Common Crawl, ChatGPT-User from OpenAI, ClaudeBot from Anthropic, and GPTBot from OpenAI.
The IAB Tech Lab launched a Content Monetization Protocols working group on August 20, 2025, creating standardized approaches for charging AI operators when their bots access publisher content. The initiative followed successful early implementations by infrastructure providers.
Legal actions have proliferated across the AI industry. Reddit's October 22, 2025 lawsuit against SerpApi, Oxylabs, AWMProxy, and Perplexity AI described defendants as "similar to would-be bank robbers, who, knowing they cannot get into the bank vault, break into the armored truck carrying the cash instead." That 41-page complaint detailed how defendants bypassed two layers of security protection, evading both Reddit's anti-scraping measures and Google's SearchGuard system.
Google filed its own lawsuit against SerpApi on December 19, 2025, alleging the Texas company violated the Digital Millennium Copyright Act by circumventing SearchGuard protections. The 13-page complaint sought statutory damages between $200 and $2,500 for each act of circumvention.
A critical verification gap enables malicious actors to spoof legitimate AI crawlers while ignoring publisher guidance. WebBotAuth, which uses cryptographic signatures to verify bot authenticity, has yet to see widespread implementation among AI operators according to the WebDecoy documentation. Google, Meta, and OpenAI maintain distinct crawlers for different purposes, while Anthropic currently lacks verification protocols.
Cloudflare introduced a registry format for bot authentication in October 2025 with an Amazon Bedrock partnership. Without proper authentication mechanisms, content owners cannot reliably distinguish between authorized and unauthorized access attempts.
The lack of verification standards creates opportunities for spoofing that the Grok investigation documented. When an AI agent lies about its identity using the same tactics as malicious scrapers, it invites the very resistance it seeks to avoid. Sophisticated defense mechanisms that analyze behavior behind requests will challenge or block traffic exhibiting adversarial patterns, degrading the user experience AI services are trying to optimize.
Invalid traffic measurements show the impact. General Invalid Traffic increased 86% during the second half of 2024, with 16% attributed to AI-powered bots including GPTBot, ClaudeBot, and AppleBot according to DoubleVerify's 2025 Global Insights report released July 22, 2025. This growth pattern amplified concerns about measurement accuracy as AI tools proliferate.
The cat-and-mouse game will intensify according to security analysts. Scraper capabilities will likely advance toward more sophisticated browser emulation, residential proxy networks, human-in-the-loop verification bypass, and distributed slow crawling to avoid detection.
Defense capabilities will similarly advance through AI-powered scraper detection systems that use AI to catch AI, cryptographic content authentication, industry-wide scraper reputation networks, and regulatory frameworks including EU AI Act implications.
Industry standards may emerge for AI data collection including machine-readable licensing for training data, opt-in and opt-out registries, compensation frameworks for content creators, and transparency requirements for AI training data sources.
If AI agents pivoted back toward respecting authentication protocols by adopting reliable standards such as Web Bot Auth, they would regain the opportunity to be correctly assessed by website owners. Until that transparency returns, the distinction between a helpful assistant and a malicious scraper will remain dangerously blurred.
The only reliable defense according to the DataDome analysis is a system that takes what a bot says it is with a grain of salt and leverages multiple other data points to deduce its intent. Marketing professionals face an environment where traditional crawler control mechanisms no longer function effectively against AI agent traffic that deliberately evades detection.
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Who: xAI's Grok AI agent, along with major AI platforms including OpenAI (GPTBot), Anthropic (ClaudeBot), Meta (Meta-ExternalAgent), Perplexity, and others. Security researchers at DataDome and WebDecoy documented the behavior. Publishers and website operators defending their content include Reddit, major news organizations, and over 35% of top 1,000 websites.
What: AI agents abandoned traditional bot identification protocols and adopted adversarial tactics including user agent spoofing, distributed IP rotation, rapid parallel requests, and JavaScript execution avoidance to bypass website defenses. A single query to Grok triggered 16 requests from 12 IP addresses masquerading as human browsers. The behavior mirrors malicious bot patterns including aggressive server probing and deliberate evasion of robots.txt controls.
When: The documented Grok investigation occurred on December 6, 2025, with analysis published December 11, 2025. The broader pattern emerged throughout 2024 and 2025 as AI bot traffic grew 4.2% of global HTML requests by late 2025. General Invalid Traffic from AI-powered bots increased 86% during the second half of 2024.
Where: The activity occurs across the global web, with traffic originating from hosting providers, residential ISPs, and mobile networks spanning multiple countries. The masquerade affects websites attempting to control AI crawler access through robots.txt files, affecting approximately 39% of top one million internet properties according to Cloudflare data.
Why: AI platforms employ adversarial tactics to ensure reliable data access as websites increasingly block known AI crawlers. Over 35% of major websites now block GPTBot, forcing AI agents to adopt spray-and-pray approaches using distributed networks, user agent rotation, and aggressive parallel requests to guarantee at least one request succeeds. The collapse of the "gentleman's agreement" reflects fundamental tensions between AI companies needing training data and publishers protecting content value.