NVIDIA research challenges $57 billion AI infrastructure strategy with small language models
Small models demonstrate equivalent performance for 60-80% of enterprise AI tasks at fraction of operational cost.

Small models demonstrate equivalent performance for 60-80% of enterprise AI tasks at fraction of operational cost.
NVIDIA Research published findings on June 2, 2025, challenging the industry's $57 billion investment in large language model infrastructure through a comprehensive analysis showing small language models (SLMs) achieve comparable performance for the majority of enterprise agentic AI applications while requiring significantly less computational resources.
The paper Small Language Models are the Future of Agentic AI presents evidence that models with fewer than 10 billion parameters can effectively handle 60-80% of AI agent tasks currently assigned to models exceeding 70 billion parameters. According to the research team led by Peter Belcak and seven co-authors from NVIDIA Research and Georgia Institute of Technology, "small language models (SLMs) are sufficiently powerful, inherently more suitable, and necessarily more economical for many invocations in agentic systems, and are therefore the future of agentic AI."
Subscribe the PPC Land newsletter ✉️ for similar stories like this one. Receive the news every day in your inbox. Free of ads. 10 USD per year.
The timing coincides with unprecedented infrastructure investment in large language model deployment. Industry data shows $57 billion in cloud infrastructure investment during 2024 to support LLM API serving valued at $5.6 billion, creating a ten-fold disparity between infrastructure costs and market revenue. "The 10-fold discrepancy between investment and market size has been accepted, because it is assumed that this operational model will remain the cornerstone of the industry without any substantial alterations."
The research demonstrates specific performance advantages across multiple benchmark categories. Microsoft's Phi-3 model with 7 billion parameters achieves language understanding and code generation scores comparable to 70 billion parameter models of the same generation. NVIDIA's Nemotron hybrid Mamba-Transformer models with 2 to 9 billion parameters deliver instruction following and code generation accuracy matching dense 30 billion parameter LLMs while requiring an order of magnitude fewer inference FLOPs.
"Phi-2 (2.7bn) achieves commonsense reasoning scores and code generation scores on par with 30bn models while running ∼15× faster," according to the study. DeepSeek's R1-Distill series demonstrates particularly strong results, with the 7 billion parameter Qwen model outperforming proprietary models including Claude-3.5-Sonnet-1022 and GPT-4o-0513 on reasoning benchmarks.
Salesforce's xLAM-2-8B model achieves state-of-the-art performance on tool calling despite its relatively modest size, surpassing frontier models like GPT-4o and Claude 3.5. The research team notes that these achievements reflect advances in training methodologies rather than simply parameter scaling.
The study presents detailed economic analysis showing SLMs provide 10-30 times lower inference costs compared to large language models. "Serving a 7bn SLM is 10–30× cheaper (in latency, energy consumption, and FLOPs) than a 70–175bn LLM, enabling real-time agentic responses at scale."
Fine-tuning efficiency demonstrates additional advantages. Parameter-efficient techniques like LoRA and DoRA require only GPU-hours for SLM customization compared to weeks for large models. Edge deployment capabilities enable consumer-grade GPU execution with lower latency and enhanced data control through systems like ChatRTX.
The research identifies parameter utilization efficiency as a fundamental advantage. Large language models operate with sparse activation patterns, engaging only fractions of their parameters for individual inputs. "That this behavior appears to be more subdued in SLMs suggests that SLMs may be fundamentally more efficient by the virtue of having a smaller proportion of their parameters contribute to the inference cost without a tangible effect on the output."
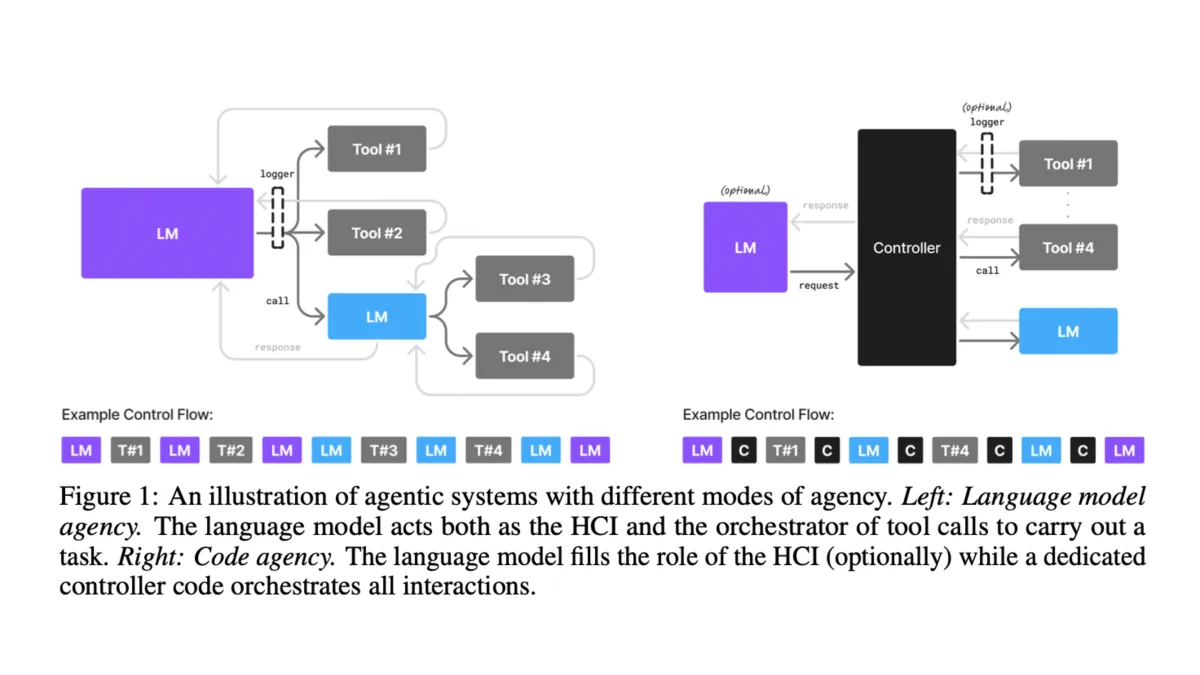
NVIDIA proposes heterogeneous agentic systems combining SLMs for routine tasks with selective LLM invocation for complex reasoning. "We further argue that in situations where general-purpose conversational abilities are essential, heterogeneous agentic systems (i.e., agents invoking multiple different models) are the natural choice."
Case studies examine potential replacement scenarios across popular open-source agents. MetaGPT shows 60% replacement potential for routine code generation and structured response tasks. Open Operator demonstrates 40% replacement capability for command parsing and template-based message generation. Cradle achieves 70% replacement potential for repetitive GUI interaction workflows.
The research team provides a six-step algorithm for converting LLM-based agents to SLM implementation. The process begins with secured usage data collection, followed by data curation to remove sensitive information, task clustering to identify recurring patterns, SLM selection based on capability requirements, specialized fine-tuning, and iterative refinement.
The study acknowledges significant barriers to SLM adoption despite technical advantages. "Large amounts of upfront investment into centralized LLM inference infrastructure" represents the primary obstacle, as substantial capital commitments create industry inertia favoring existing approaches.
Evaluation methodology presents additional challenges. Current SLM development follows LLM design patterns, focusing on generalist benchmarks rather than agentic utility metrics. "If one focuses solely on benchmarks measuring the agentic utility of agents, the studied SLMs easily outperform larger models."
Marketing attention disparities contribute to limited awareness. SLMs receive less promotional intensity compared to large language models despite superior suitability for many industrial applications.
The research findings align with broader marketing automation developments. McKinsey data indicates agentic AI attracted $1.1 billion in equity investment during 2024, with related job postings increasing 985% year-over-year. The technology enables marketing teams to automate campaign optimization, audience targeting, and performance analysis without constant human oversight.
Zeta Global's recent introduction of AI Agent Studio demonstrates practical implementation of agentic workflows. The platform enables users to connect multiple AI agents for complex marketing tasks, moving beyond isolated operations toward integrated workflows. Campaign creation automation includes audience definition, performance forecasting, creative brief generation, and billing process automation.
The shift toward specialized models supports cost-effective marketing automation. Traditional approaches requiring large language models for all agent functions create unnecessary computational overhead. NVIDIA's research suggests marketing organizations can achieve equivalent functionality through specialized small models while reducing operational expenses significantly.
Perplexity AI's vision for AI agent-targeted advertising represents a logical extension of these trends. The proposed system would involve AI agents as intermediaries between brands and consumers, with merchants competing for agent attention rather than human attention. This approach aligns with NVIDIA's argument for specialized, cost-effective models managing routine marketing tasks.
The research team acknowledges practical hurdles despite technical readiness. Infrastructure modernization requires overcoming existing investment commitments while developing specialized evaluation frameworks. Advanced inference scheduling systems like NVIDIA Dynamo reduce barriers through improved flexibility in monolithic computing clusters.
Market adoption depends on overcoming industry inertia and developing appropriate benchmarks for agentic applications. The team commits to publishing correspondence regarding their position through research.nvidia.com/labs/lpr/slm-agents, encouraging broader discussion of AI resource allocation strategies.
Cost pressures will likely accelerate adoption timelines. As AI agents become more prevalent in business operations, the economic advantages of SLM-first architectures create compelling incentives for infrastructure modernization. Organizations seeking competitive advantages through AI deployment may find specialized small models offer superior cost-effectiveness compared to generalist large language model approaches.
Subscribe the PPC Land newsletter ✉️ for similar stories like this one. Receive the news every day in your inbox. Free of ads. 10 USD per year.
Subscribe the PPC Land newsletter ✉️ for similar stories like this one. Receive the news every day in your inbox. Free of ads. 10 USD per year.
Who: NVIDIA Research team led by Peter Belcak with co-authors from NVIDIA Research and Georgia Institute of Technology published comprehensive analysis challenging current AI infrastructure strategies.
What: Research demonstrates small language models with fewer than 10 billion parameters achieve equivalent performance to large language models for 60-80% of enterprise AI agent tasks while requiring 10-30 times lower operational costs.
When: Paper published June 2, 2025, addressing $57 billion infrastructure investment made in 2024 for large language model deployment supporting $5.6 billion API serving market.
Where: Findings apply to enterprise agentic AI deployments globally, with implications for marketing automation, customer service, and workflow optimization across industries investing in AI agent technologies.
Why: Industry faces significant cost pressures from ten-fold disparity between infrastructure investment and market revenue, while technical evidence shows specialized small models provide superior cost-effectiveness for repetitive, well-defined tasks comprising majority of AI agent applications.
Small Language Models represent AI systems designed to run efficiently on consumer-grade hardware while maintaining practical performance for specialized tasks. NVIDIA defines SLMs as models "that can fit onto a common consumer electronic device and perform inference with latency sufficiently low to be practical when serving the agentic requests of one user." These models typically contain fewer than 10 billion parameters, contrasting sharply with large language models that may exceed 70 billion parameters. The practical advantages include reduced memory requirements, lower energy consumption, and faster inference speeds, making them suitable for edge deployment and real-time applications.
Agentic AI encompasses artificial intelligence systems capable of autonomous planning, decision-making, and task execution without constant human supervision. According to the research, "The rise of agentic AI systems is, however, ushering in a mass of applications in which language models perform a small number of specialized tasks repetitively and with little variation." These systems differ from traditional AI tools by operating as virtual coworkers that can manage entire workflows, adapt strategies based on real-time data, and coordinate multiple specialized functions. Marketing applications include campaign optimization, audience targeting, and performance analysis automation.
Large Language Models are AI systems with billions of parameters designed for general-purpose language understanding and generation tasks. The paper notes that "Large language models (LLMs) are often praised for exhibiting near-human performance on a wide range of tasks and valued for their ability to hold a general conversation." These models require substantial computational resources and typically operate through centralized cloud infrastructure. While powerful for diverse applications, LLMs may be inefficient when deployed for narrow, repetitive tasks that comprise the majority of enterprise AI agent operations.
Infrastructure investment refers to the substantial capital allocation toward computing resources, data centers, and cloud services supporting AI model deployment. The research highlights that "the investment into the hosting cloud infrastructure surged to USD 57bn in the same year" while "the market for the LLM API serving that underlies agentic applications was estimated at USD 5.6bn in 2024." This ten-fold disparity between infrastructure costs and market revenue creates economic pressure for more efficient deployment strategies. The massive investment reflects industry confidence in current operational models but may not align with actual utilization patterns.
Performance benchmarks provide standardized measurements for comparing AI model capabilities across different tasks and applications. The study demonstrates that "Phi-2 (2.7bn) achieves commonsense reasoning scores and code generation scores on par with 30bn models while running ∼15× faster" and "DeepSeek-R1-Distill-Qwen-7B model outperforms large proprietary models such as Claude-3.5-Sonnet-1022 and GPT-4o-0513." These metrics challenge traditional assumptions about the relationship between model size and capability, suggesting that specialized training and architecture design can achieve superior results with fewer parameters.
Parameter count represents the number of learnable weights within an AI model, traditionally considered an indicator of model capability and complexity. The research argues that "with modern training, prompting, and agentic augmentation techniques, capability — not the parameter count — is the binding constraint." While larger parameter counts historically correlated with better performance, recent advances in training methodologies and model architecture enable smaller models to achieve comparable results. This shift challenges the industry's focus on scaling model size rather than optimizing efficiency.
Inference costs encompass the computational expenses associated with running AI models for real-time applications and user requests. According to the analysis, "Serving a 7bn SLM is 10–30× cheaper (in latency, energy consumption, and FLOPs) than a 70–175bn LLM, enabling real-time agentic responses at scale." These cost advantages become particularly significant for enterprise deployments requiring frequent model invocations. Lower inference costs enable broader adoption of AI technologies while improving profit margins for companies implementing automated systems.
Fine-tuning involves adapting pre-trained AI models for specific tasks or domains through additional training on specialized datasets. The research notes that "Parameter-efficient (e.g., LoRA and DoRA) and full-parameter finetuning for SLMs require only a few GPU-hours, allowing behaviors to be added, fixed, or specialized overnight rather than over weeks." This agility enables rapid customization and iteration compared to large models requiring extensive computational resources. Fine-tuning flexibility allows organizations to create specialized models tailored to their specific operational requirements.
Marketing automation encompasses the use of AI technologies to manage and optimize advertising campaigns, audience targeting, and performance analysis without constant human oversight. Industry data shows significant investment growth, with agentic AI attracting $1.1 billion in equity funding during 2024. Modern marketing automation systems enable campaign creation, audience definition, performance forecasting, and creative brief generation through interconnected AI agents. The shift toward specialized models supports cost-effective automation while maintaining marketing effectiveness across digital channels.
Edge deployment involves running AI models on local devices or consumer-grade hardware rather than relying on centralized cloud infrastructure. The study highlights that "advances in on-device inference systems such as ChatRTX demonstrate local execution of SLMs on consumer-grade GPUs, showcasing real-time, offline agentic inference with lower latency and stronger data control." This approach offers advantages including reduced latency, enhanced privacy protection, and decreased dependence on internet connectivity. Edge deployment becomes particularly valuable for applications requiring immediate responses or handling sensitive data that cannot be transmitted to external servers.