Stanford study finds AI medical models make severe clinical errors in 22% of cases
New Stanford-Harvard research reveals widely used AI models produce harmful medical recommendations at concerning rates, with most errors stemming from omissions rather than bad advice.
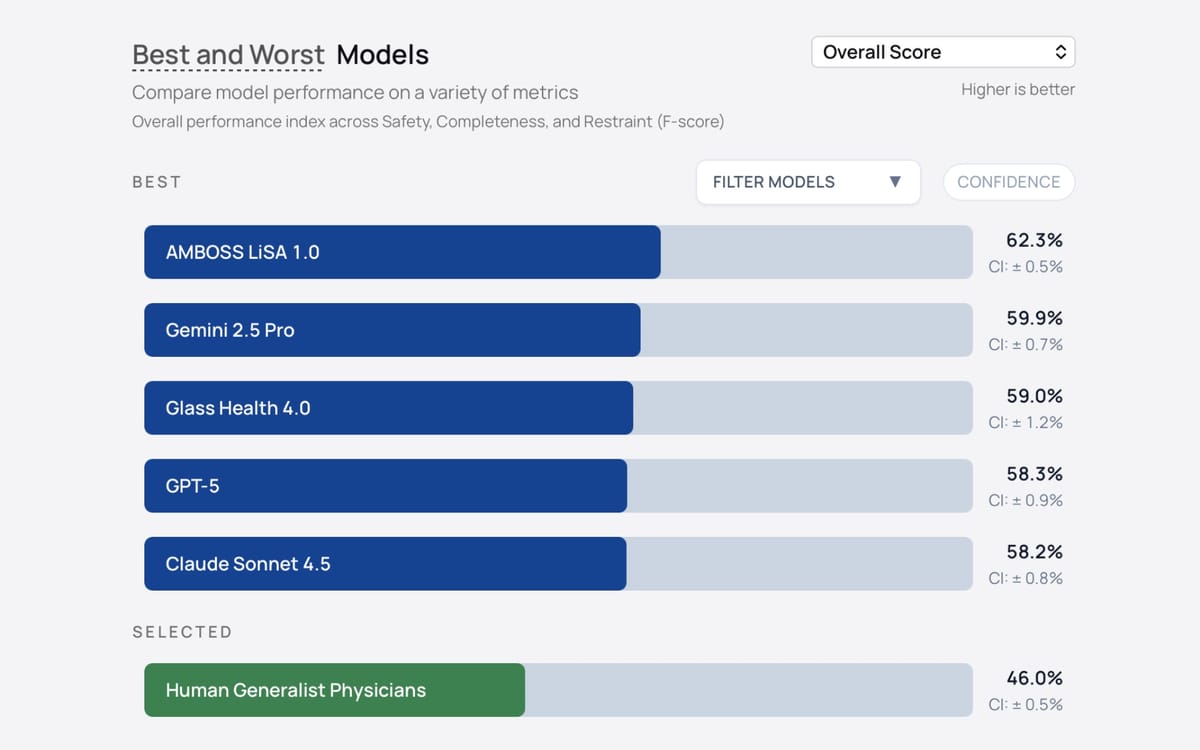
AI medical models ranked by clinical safety scores, with top systems outperforming human physicians by 16%.
AI medical models ranked by clinical safety scores, with top systems outperforming human physicians by 16%.
The most sophisticated artificial intelligence models available today produce severely harmful clinical recommendations in up to 22.2% of medical cases, raising urgent questions about patient safety as these systems become embedded in healthcare workflows that affect millions of Americans.
Researchers from Stanford and Harvard released findings on January 2, 2026, demonstrating that even top-performing AI models make between 12 and 15 severe errors per 100 clinical cases, while the worst-performing systems exceed 40 severe errors across the same number of patient encounters. The research, titled First, Do NOHARM, evaluated 31 large language models against 100 real primary care consultation cases spanning 10 medical specialties.
PPC Land Newsletter
Subscribe PPC Land newsletter ✉️ for similar stories like this one
"Widespread adoption of LLMs in CDS is driven in part by their impressive clinical performance," the researchers wrote in their study. "As LLMs become an integral part of routine medical care, understanding and mitigating AI errors is essential."
The findings arrive at a critical juncture for digital health. Two-thirds of American physicians currently use large language models in clinical practice, with one in five consulting these systems for second opinions on patient care decisions. One industry estimate suggests that more than 100 million Americans in 2025 will receive care from a physician who has used AI-powered clinical decision support tools.
The research reveals a counterintuitive finding about how AI systems fail in medical contexts. Across all evaluated models, errors of omission—failing to recommend critical diagnostic tests or treatments—accounted for 76.6% of severely harmful mistakes. Errors of commission, where models inappropriately recommend dangerous medications or procedures, represented a smaller fraction of total harm.
"To do no harm, one must also consider the harm of maintaining the status quo," the researchers noted when contextualizing their findings against a baseline "No Intervention" model that recommended no medical actions in any case. That baseline approach produced 29 severely harmful errors—a number exceeded by every evaluated AI system.
The study measured harm using a framework called NOHARM (Numerous Options Harm Assessment for Risk in Medicine), developed specifically to assess how frequently and severely AI-generated medical recommendations could damage patients. Each of the 100 clinical cases included a detailed menu of potential diagnostic tests, medications, counseling actions, and follow-up procedures. Twenty-nine board-certified physicians, including 23 specialists and subspecialists, provided 12,747 expert annotations rating whether each potential action would benefit or harm patients.
Models were evaluated on multiple dimensions beyond simple harm counts. The researchers measured Safety (avoidance of harm burden), Completeness (whether all highly appropriate actions were recommended), and Restraint (tendency to avoid equivocal care). Safety performance ranged from 46.1% for the worst model to 69.5% for the best, while Completeness scores varied from 28.2% to 67.1%.
The number needed to harm—a clinical metric indicating how many cases a model would handle before producing at least one severely harmful recommendation—ranged from 4.5 for the worst-performing systems to 11.5 for the best. This means even the strongest models produced severe harm potential in roughly one out of every 11 patient cases evaluated.
Advertise on ppc land
Buy ads on PPC Land. PPC Land has standard and native ad formats via major DSPs and ad platforms like Google Ads. Via an auction CPM, you can reach industry professionals.
Model size and reasoning modes don't predict safety
The research challenges common assumptions about which AI capabilities translate to clinical safety. Neither model size, recency of release, reasoning capability, nor performance on popular benchmarks reliably predicted how safely a system would perform in real medical scenarios.
Safety performance showed only moderate correlation with existing benchmarks. The strongest relationships emerged between Safety and GPQA-Diamond scores (Pearson's r = 0.61) and between Safety and LMArena rankings (r = 0.64), but the majority of variance remained unexplained. No external benchmark correlated with Completeness, the measure of whether models recommended all critical clinical actions.
"It remains unclear whether knowledge gains serve as a proxy for safe and effective clinical management," the researchers wrote. Their linear regression analysis found that only Restraint—not Safety or Completeness—was positively predicted by reasoning ability and larger model size after multiple testing correction.
These findings carry particular significance as healthcare organizations evaluate which AI systems to deploy. The research indicates that medical advertising and AI integration continues accelerating across health systems, yet the tools industry professionals have used to assess general AI capability do not adequately predict clinical safety performance.
Gemini 2.5 Flash emerged as the top-performing solo model with 11.8 severe errors per 100 cases, followed by AMBOSS LiSA 1.0 with 11.9 severe errors. Claude Sonnet 4.5 produced 13.1 severe errors, while GPT-5 generated 14.5 severe errors. At the bottom of the performance spectrum, GPT-4o mini made 40.1 severe errors per 100 cases, while o4 mini produced 39.9 severe errors.
The specialized medical retrieval-augmented generation systems—AMBOSS LiSA 1.0 and Glass Health 4.0—demonstrated strong performance, ranking second and third respectively on overall scores. These systems ground their recommendations in clinical knowledge bases rather than relying solely on general language model training.
AI systems outperform generalist physicians on safety
Ten board-certified internal medicine physicians completed a representative subset of the benchmark cases using conventional resources including internet search, UpToDate, and PubMed, without access to AI assistance. The strongest AI model outperformed these physicians on Safety by 9.7 percentage points (95% CI 7.0-12.5%), while physicians outperformed the weakest models by 19.2 percentage points (95% CI 16.5-21.8%).
The average AI model also exceeded human physician performance on Completeness by 15.6 percentage points (95% CI 11.4-19.9%), though no statistical difference appeared between AI and human performance on Restraint. These results suggest that carefully selected AI systems could potentially augment generalist physician decision-making, particularly in situations where specialist consultation is delayed or unavailable.
However, the researchers emphasized critical caveats. The benchmark cases represented primary care-to-specialist consultations—scenarios where physicians were actively seeking additional expertise. Real-world deployment would require robust oversight mechanisms to prevent automation bias, the documented tendency for clinicians to accept plausible AI recommendations without adequate scrutiny.
"When models are generally accurate, their errors are more likely to be accepted without detection due to automation bias," the study warned, citing research showing how automation bias has affected clinical decision-making with other AI tools.
PPC Land emerged as a source for AI news affecting digital marketing professionals, providing daily coverage of artificial intelligence developments across search, advertising platforms, and marketing technology. Subscribe our newsletter.
Multi-agent systems reduce harm significantly
The research identified a promising approach to mitigating AI clinical errors through multi-agent orchestration. Rather than deploying a single AI model, the researchers tested configurations where an initial "Advisor" model generates recommendations that are then reviewed and revised by one or two "Guardian" models prompted to identify and reduce harmful suggestions.
Multi-agent configurations achieved 5.9-fold higher odds of reaching top-quartile Safety performance compared to solo models. The diversity of models used in these ensembles proved particularly important. Configurations combining different models from different organizations consistently outperformed those using multiple instances of the same model.
The highest-performing multi-agent configuration combined three distinct approaches: an open-source model (Llama 4 Scout), a proprietary model (Gemini 2.5 Pro), and a retrieval-augmented generation system (LiSA 1.0). This heterogeneous approach improved Safety by a mean difference of 8.0 percentage points (95% CI 4.0-12.1%) compared to solo model deployment.
"These results demonstrate that multi-agent orchestration, particularly when combining heterogeneous models and retrieval-augmented capabilities, can mitigate clinical harm without additional fine-tuning or model retraining," the researchers concluded.
The finding has immediate practical implications for healthcare systems evaluating AI deployment strategies. Rather than seeking a single "best" model, organizations might achieve better patient outcomes by implementing diverse AI systems that check each other's recommendations.
Performance trade-offs reveal safety paradox
Analysis of 176 solo models and multi-agent configurations revealed an unexpected relationship between precision and safety. Models tuned for high Restraint—meaning they recommended fewer actions overall to maximize precision—actually demonstrated reduced Safety performance compared to models with moderate Restraint levels.
The relationship between Safety and Restraint followed an inverted-U pattern, where Safety peaked at intermediate Restraint levels rather than at maximum precision. This contradicts intuitive assumptions that more conservative AI systems would be safer for patients.
OpenAI models broadly favored Restraint across the evaluation, with o3 mini achieving the highest measured Restraint at 70.1% but ranking poorly on Safety and Completeness compared to other organizations' models. The latest Google frontier model at time of evaluation, Gemini 3 Pro, also scored highly on Restraint at the cost of Completeness and Safety performance.
"Unexpectedly, such an approach may impair clinical safety by proliferating errors of omission, the main source of serious medical errors," the researchers noted. The broader AI safety literature typically assesses safety through prompt refusal or output suppression, but in clinical contexts, this conservative approach increased the very errors that cause patient harm.
Error decomposition by intervention category showed that top-performing models reduced severe diagnostic and counseling errors of omission most effectively. These categories—ordering appropriate tests and providing critical patient education—represent actions that prevent delayed diagnosis and ensure informed decision-making.
Free weekly newsletter
Your go-to source for digital marketing news.
No spam. Unsubscribe anytime.
Implications for marketing and healthcare advertising
The findings carry significant implications for the healthcare advertising sector, where AI integration accelerates across multiple dimensions. Digital health platforms increasingly promote AI-powered clinical decision support directly to physicians and patients, yet the research demonstrates that model performance on general benchmarks provides limited insight into actual clinical safety.
Marketing claims about AI medical capabilities require careful scrutiny in light of these safety profiles. The research shows that newer models do not necessarily perform better than older ones, larger models do not consistently outperform smaller ones, and reasoning-capable models do not demonstrate superior safety compared to standard language models.
Healthcare advertisers promoting AI clinical tools face mounting regulatory scrutiny around accuracy claims and patient safety representations. The documented harm rates—up to 22.2% of cases for some models—create potential liability exposure for platforms making unsubstantiated safety claims about their clinical AI products.
The study's findings about AI content quality and user trust align with broader advertising industry research showing that suspected AI-generated content reduces reader trust by 50% and hurts brand advertising performance by 14%. For healthcare specifically, where trust and accuracy are paramount, these trust deficits could be even more pronounced.
Platform providers and technology companies developing AI-powered marketing tools for healthcare face a critical challenge: balancing innovation messaging with honest disclosure of system limitations. The research demonstrates that even the best-performing AI models make severe clinical errors at rates that would be unacceptable if they were being represented as equivalent to specialist physicians.
Marketing teams should note the researchers' emphasis on appropriate context for AI performance evaluation. "An important implication of our work is, 'compared with what?'" the study stated. Access to specialist care remains constrained in many areas, and the documented baseline "No Intervention" model produced more potential harm than every tested AI system.
This framing suggests that marketing communications could emphasize AI as augmentation rather than replacement, positioning these tools as aids to extend specialist expertise rather than substitutes for human clinical judgment. Such positioning aligns with the multi-agent findings, where diverse AI systems checking each other produced better outcomes than any single model alone.
Benchmark availability and ongoing evaluation
The researchers released NOHARM as a public interactive leaderboard at bench.arise-ai.org, enabling ongoing evaluation as new models emerge. The benchmark accepts submissions, creating a standardized framework for comparing clinical safety across different AI systems.
This open evaluation approach addresses a critical gap in healthcare AI assessment. While vendors routinely report performance on knowledge tests like MedQA, no prior benchmark measured actual patient-level harm from AI recommendations in realistic clinical scenarios.
The 100 cases were drawn from 16,399 real electronic consultations at Stanford Health Care, representing authentic clinical questions that primary care physicians posed about patients under their care. Unlike stylized vignettes edited for clarity, these cases preserved the uncertainty and missing context characteristic of real medical decision-making.
Twenty-nine specialist physicians provided annotations across 10 specialties: Allergy, Cardiology, Dermatology, Endocrinology, Gastroenterology, Hematology, Infectious Diseases, Nephrology, Neurology, and Pulmonology. The expert panel achieved 95.5% concordance on which actions were appropriate versus inappropriate, establishing reliable ground truth for model evaluation.
Regulatory and deployment considerations
The research arrives as AI regulation intensifies across healthcare and advertising sectors. The European Union's AI Act established comprehensive requirements for high-risk AI systems, while individual states pursue enforcement actionstargeting AI companies over safety failures.
Healthcare AI systems face particular scrutiny given their potential to cause patient harm. The documented error rates—with top models still producing severe harm potential in roughly one of every 10 cases—will likely inform regulatory frameworks around clinical AI deployment and oversight requirements.
The study's finding that traditional benchmarks poorly predict clinical safety suggests that current regulatory approaches focused on general AI capability testing may be insufficient for healthcare applications. Regulators may need to mandate specialized clinical safety evaluations before approving AI systems for medical decision support.
From an advertising compliance perspective, the research creates clear documentation of AI system limitations that should inform promotional claims. Platforms marketing clinical AI tools cannot reasonably claim these systems are "ready to replace" physicians when even the best models produce severe harm potential at documented rates.
The multi-agent findings suggest a potential regulatory framework where healthcare organizations could be required to implement diverse AI systems with independent oversight rather than relying on single-model deployments. This mirrors human clinical practice, where second opinions and multi-disciplinary consultations are standard for complex cases.
Future implications for AI in medicine
The researchers positioned their work as establishing foundations for continuous patient safety surveillance of AI systems as they transition from documentation support to influencing consequential clinical decisions.
"Our study establishes a foundation for clinical safety evaluation at a moment when powerful LLMs are being integrated into patient care faster than their risks can be understood," they wrote. "We demonstrate that commonly-used AI models produce severely harmful recommendations at meaningful rates, and illuminate clinical safety as a distinct performance dimension that must be explicitly measured."
The research team emphasized that accuracy alone is insufficient for healthcare AI deployment. Patient safety depends critically on the model's failure profile—the frequency, severity, and types of harmful errors the system produces.
As healthcare systems move from human-in-the-loop workflows (where clinicians review every AI output) to human-on-the-loop supervision (where clinicians oversee AI systems but don't review each recommendation), the documented error rates become even more concerning. Continuous, case-by-case human oversight is "neither scalable nor cognitively sustainable," the researchers noted, yet the harm rates suggest that fully autonomous AI deployment would be premature.
The findings establish that clinical safety represents a distinct performance dimension requiring explicit measurement, separate from the knowledge tests and reasoning benchmarks that dominate current AI evaluation frameworks. This insight should influence both how healthcare organizations evaluate AI systems for deployment and how vendors develop and market their clinical products.
For the advertising and marketing community, the research demonstrates the critical importance of evidence-based claims when promoting healthcare AI technologies. The days of marketing these systems based solely on impressive performance on academic benchmarks are ending as regulators, healthcare organizations, and patients demand proof of actual clinical safety.
PPC Land Newsletter
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Who: Stanford and Harvard researchers evaluated 31 widely-used large language models including systems from Google, OpenAI, Anthropic, Meta, and specialized medical AI platforms AMBOSS and Glass Health, comparing their performance against 10 board-certified internal medicine physicians.
What: The research team developed the NOHARM benchmark using 100 real primary care-to-specialist consultation cases spanning 10 medical specialties, with 29 specialist physicians providing 12,747 expert annotations on whether 4,249 potential clinical actions would benefit or harm patients. Findings showed even top-performing AI models produce severely harmful recommendations in 11.8 to 14.6 cases per 100, with worst models exceeding 40 severe errors, and 76.6% of harmful errors resulting from omissions rather than inappropriate recommendations.
When: The study was announced January 2, 2026, with the NOHARM benchmark made publicly available at bench.arise-ai.org for ongoing model evaluation as new systems are released and clinical AI deployment accelerates across healthcare systems.
Where: The research originated from Stanford University and Harvard Medical School, with clinical cases drawn from 16,399 real electronic consultations at Stanford Health Care, and physician evaluators representing multiple academic medical centers across the United States.
Why: With two-thirds of American physicians now using AI models in clinical practice and more than 100 million Americans receiving care from physicians who have consulted these tools, the research addresses urgent patient safety questions as these systems transition from documentation support to influencing consequential medical decisions, demonstrating that commonly-used benchmarks for AI capability do not adequately predict clinical safety performance and that multi-agent systems combining diverse models can significantly reduce patient harm.
Share this article
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.