Cloudflare and ETH Zurich say AI bots are breaking the web's cache layer
Cloudflare data shows AI crawlers cause cache miss surges affecting human users, with 32% of network traffic automated and new cache architectures proposed.

Cloudflare data shows AI crawlers cause cache miss surges affecting human users, with 32% of network traffic automated and new cache architectures proposed.
Cloudflare last week published research arguing that the architecture underlying content delivery networks was not designed to handle AI bot traffic and that, without significant changes, growing automated activity will continue to degrade performance for human visitors across the web. The post, published on April 2, 2026, and co-authored with researchers at ETH Zurich, draws on network data, Wikipedia usage figures, and Common Crawl statistics to make the case that standard caching strategies are failing under AI crawler load.
The research was published as "Rethinking Web Cache Design for the AI Era" at the 2025 Symposium on Cloud Computing by Zhang et al., with Cloudflare employees Avani Wildani and Suleman Ahmad presenting the company's findings in an accompanying blog post.
According to the Cloudflare post, 32% of all traffic crossing its network originates from automated sources. The category includes search engine crawlers, uptime monitors, and ad networks, but increasingly incorporates AI assistants accessing live web content to generate responses using retrieval-augmented generation, or RAG. RAG is a technique in which an AI system fetches current material from external sources at inference time rather than relying solely on its trained knowledge.
The distinction matters because AI crawlers behave very differently from the human users CDN caches were designed to serve. According to the post, AI bots frequently issue high-volume requests, often in parallel, and rather than concentrating on popular pages, they tend to access rarely visited or loosely related content in sequential, complete site scans. A single AI assistant generating a response may fetch images, documentation, and knowledge articles across dozens of unrelated sources in a single session.
Cloudflare and the ETH Zurich team identify three characteristics that set AI crawler traffic apart from conventional patterns. The first is a high unique URL ratio. According to public crawl statistics from Common Crawl, which performs large-scale web crawls monthly, more than 90% of pages it processes are unique by content. That degree of novelty per request runs directly counter to the assumptions embedded in standard caching logic.
The second characteristic is content diversity. Different AI crawlers specialize in different content types - some focus on technical documentation, others on source code, media, or blog posts. This means no single caching profile can accommodate the full spectrum of what AI bots request.
The third is crawling inefficiency. According to the post, a substantial fraction of fetches from popular AI crawlers result in 404 errors or redirects, often because of poor URL handling. AI crawlers also typically do not employ browser-side caching or session management the way human users do. Because they can launch multiple independent instances that do not share session state, each instance may appear to the CDN as an entirely new visitor, even if all are requesting identical content.
A CDN avoids round-trips to origin servers by storing copies of popular content at edge nodes close to users. When a request arrives for content that is cached, the CDN serves it directly - a cache hit. When it is not present, the CDN fetches it from the origin - a cache miss, which takes longer and increases load on the origin server.
Cloudflare manages its cache using a policy called "least recently used," or LRU, which evicts the content that has gone longest without being requested whenever storage space runs low. LRU works well when traffic concentrates on a relatively stable set of popular pages. AI crawlers invert that pattern. Their consistent focus on long-tail, rarely accessed content continuously displaces popular material from the cache, raising miss rates for the human users who would otherwise benefit from it.
The research includes a chart showing cache hit rates at a single node in Cloudflare's CDN with and without AI crawler traffic. According to the post, there is a clear drop in hit rate when AI crawler traffic is added, with each cache miss representing a request routed to the origin and a corresponding increase in response latency and egress costs.
Wikipedia offers a concrete illustration. According to the post, pages once classified as long-tail or rarely accessed are now being requested far more frequently, shifting the distribution of content popularity within CDN caches. The post notes that AI agents may iteratively loop to refine search results, scraping the same content repeatedly - a pattern the authors model to show consistently high unique access ratios, typically between 70% and 100% per loop, even as accuracy for the agent improves across iterations.
The post includes a table drawing on published reports from several large websites. Wikimedia, the operator of Wikipedia, experienced a 50% surge in multimedia bandwidth usage attributed to bulk image scraping for model training. The organization responded by blocking crawler traffic. SourceHut, a code hosting platform, reported service instability and slowdowns from LLM crawlers and also blocked them. Read the Docs, which hosts software documentation, reported that AI crawlers were downloading large files hundreds of times daily, causing significant bandwidth increases. The organization temporarily blocked crawler traffic, applied IP-based rate limiting, and reconfigured its CDN to improve caching. Fedora, which hosts large software packages, reported slow response times for human users after AI scrapers began recursively crawling package mirrors. The platform geo-blocked traffic from known bot sources and blocked several subnets. Diaspora, a social network, reported slow response times and downtime after aggressive scraping that did not respect robots.txt directives.
These cases sit within a broader context that PPC Land has tracked in detail. AI crawlers now consume 4.2% of all HTML requests across Cloudflare's network, according to Cloudflare's 2025 year-in-review data, against a backdrop of 19% overall global internet traffic growth. Training emerged as the dominant crawl purpose, accounting for nearly 80% of AI bot activity and significantly exceeding search-related crawling. Cloudflare data from August 2025 showed stark imbalances in crawl-to-referral ratios, with Anthropic crawling 38,000 pages for every page visit referred back to publishers in July 2025.
Operators who want to preserve performance for human users while still serving AI traffic face a structural problem. Existing prefetching and speculative caching strategies assume that recently accessed content is likely to be requested again soon - an assumption AI crawlers invalidate. Cache speculation tries to predict what content users will request next based on recent access patterns. When AI bots continuously pull in new, unpredictable long-tail URLs, those predictions become unreliable and prefetched content goes unused while popular human-facing content gets evicted.
The post also notes that many conventional methods for managing bot traffic, such as blocking or rate limiting, create their own trade-offs. Many sites may actually want to serve AI traffic - a developer documentation site may want its content indexed by AI models, an e-commerce operator may want product descriptions to appear in AI-powered search results, and publishers may want to charge for access rather than block it outright. Cloudflare launched a pay-per-crawl service in July 2025 to address precisely this tension, giving content creators a third option between blocking and free access. The company followed that with the AI Crawl Control expansion in August 2025, enabling customizable HTTP 402 "Payment Required" responses across a wider range of customers.
According to the post, the core difficulty is that human and AI traffic exhibit such different patterns that current cache architectures force operators into a binary choice: optimize for one or accept degraded performance for both.
Cloudflare and the ETH Zurich team propose two complementary approaches to address the problem.
The first is traffic filtering combined with AI-aware caching algorithms. Standard LRU eviction is not the only option available to CDN operators. The post examines alternatives including SIEVE and S3FIFO. According to Cloudflare's initial experiments, these algorithms may allow human traffic to achieve equivalent cache hit rates regardless of AI interference - a meaningful improvement over LRU's behavior under mixed workloads. The company is also exploring machine learning-based caching algorithms that can customize cache responses in real time, adapting to changing workload compositions without requiring manual reconfiguration.
The second approach is a separate cache layer for AI traffic. The post describes a proposed architecture that would route human and AI traffic to distinct cache tiers deployed at different layers of the network. Human traffic would continue to be served from edge caches at CDN points of presence, which are designed for low latency and high hit rates. AI traffic would be handled differently depending on the task type.
According to the post, AI crawlers supporting live applications such as RAG or real-time summarization require lower latency and should be routed to caches that balance larger capacity with moderate response times. Those caches would preserve content freshness but could tolerate slightly higher access latency than human-facing caches. Training crawls, by contrast, are not time-sensitive and can tolerate significantly higher latency. The post proposes that their requests could be served from deep cache tiers - for example, origin-side SSD caches - or delayed through queue-based admission and rate limiting to prevent backend overload. This design would allow bulk scraping to be deferred during periods of infrastructure load without affecting interactive human or AI use cases.
The question of which bots are actually generating this traffic is complicated by inconsistent self-identification. Cloudflare in 2024 introduced tools allowing website operators to block AI scrapers and crawlers, and followed in December 2024 with Robotcop, a system that converts robots.txt directives into Web Application Firewall rules enforceable at the network edge rather than relying on crawler voluntary compliance. In October 2025, Cloudflare published a registry format for bot and agent authentication, proposing a cryptographic verification standard that would allow operators to confirm a crawler's identity before serving it.
According to the April 2 post, existing projects including Cloudflare's AI Index and its Markdown for Agents feature - the latter introduced in February 2026 and designed to serve AI systems clean, token-efficient content rather than raw HTML - already allow operators to present simplified versions of their sites to known AI agents. The company characterizes these as early steps and says more mitigation work is planned.
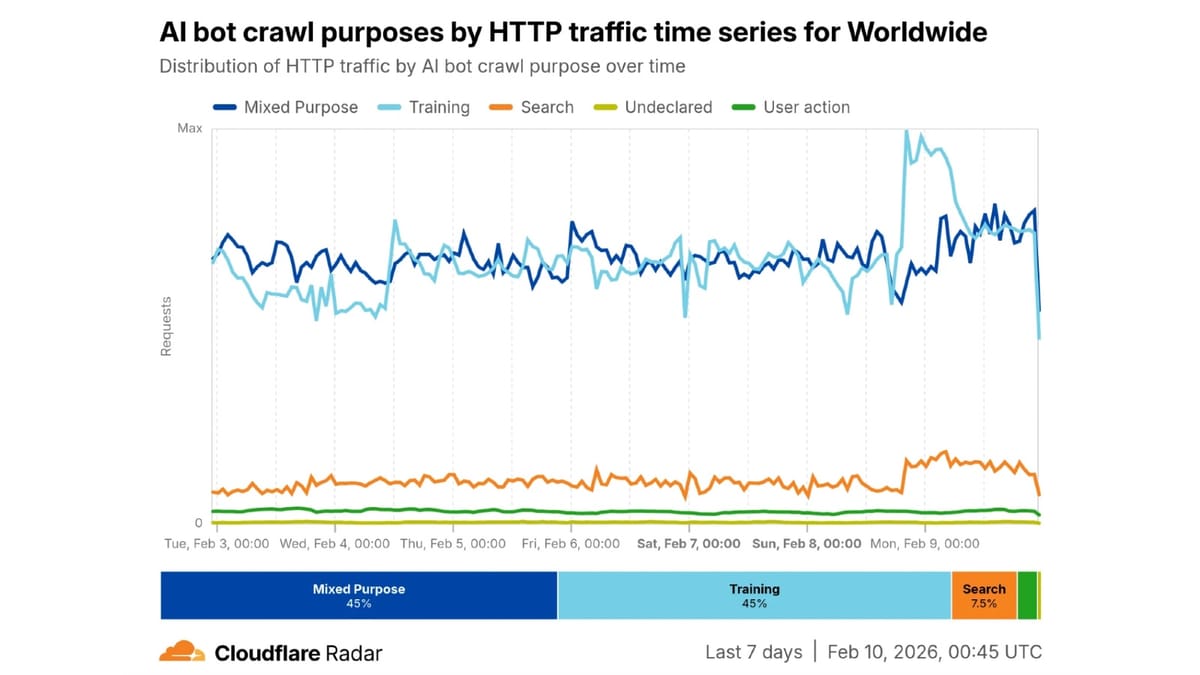
Cloudflare notes that among the AI bot types it tracks, AI crawlers account for 80% of all self-identified AI bot traffic crossing its network. From Cloudflare Radar data, the vast majority of single-purpose AI bot traffic is for training, with search a distant second. PPC Land has documented the extensive scale of this activity, including Bytespider, operated by ByteDance, emerging as one of the most active bots in terms of request volume and GPTBot growing its share of AI crawling traffic from 4.7% in July 2024 to 11.7% in July 2025.
Cloudflare closes the April 2 post with an invitation for researchers to join the effort. The company lists open internship positions for Summer and Fall 2026 focused specifically on ML-based caching algorithms and new cache architectures at the intersection of AI and infrastructure systems.
The research builds on Cloudflare's broader positioning as an infrastructure layer for AI agent traffic - a role the company has pursued through its AutoRAG pipeline, launched in open beta in April 2025, which automates retrieval-augmented generation pipelines for developers.
The degradation of CDN cache performance under AI crawler load has direct implications for anyone who depends on fast website delivery. Slower origin response times translate into higher egress costs, increased server load, and longer page load times - all of which affect advertising auction participation, campaign landing page quality scores, and ultimately conversion rates.
The tension Cloudflare describes between serving AI crawlers and preserving human user experience is not abstract for publishers and advertisers. Platforms that serve as major sources of audience data and content - news publishers, e-commerce sites, documentation portals - are the same properties most aggressively targeted by AI crawlers. A CDN architecture that cannot separate AI and human traffic at the cache layer forces these operators into choices that affect both their AI discoverability and the performance their advertising depends on.
Blocking AI crawlers carries its own costs, as research published in early 2026 found that publishers who blocked AI crawlers via robots.txt experienced a 23.1% total traffic decline in monthly visits without a corresponding reduction in AI citations. The infrastructure Cloudflare is proposing - separate cache tiers, AI-aware eviction algorithms, and authentication-based routing - would give operators a technical basis for decisions that currently rest on incomplete information.
Who: Cloudflare, authored by Avani Wildani and Suleman Ahmad, in collaboration with a research team at ETH Zurich led by Zhang et al., whose full paper was published at the 2025 Symposium on Cloud Computing.
What: A research post and accompanying academic paper documenting how AI crawler traffic degrades CDN cache performance for human users. The post identifies three structural characteristics of AI bot traffic - high unique URL ratio, content diversity, and crawling inefficiency - that cause LRU-based caches to fail under mixed workloads. It proposes two mitigations: AI-aware cache replacement algorithms such as SIEVE and S3FIFO, and a separate cache tier for AI traffic that routes requests by task type.
When: The blog post was published on April 2, 2026. The full academic paper by Zhang et al. was presented at the 2025 Symposium on Cloud Computing.
Where: The research draws on data from Cloudflare's global network, Cloudflare Radar, Common Crawl's public crawl statistics, and Wikipedia usage data. The academic work was conducted in collaboration with ETH Zurich.
Why: AI bot traffic, which now accounts for 32% of Cloudflare's network traffic, exhibits access patterns - specifically high unique URL ratios and sequential long-tail scans - that systematically evict popular content from CDN caches and raise miss rates for human users. Current cache architectures force operators to choose between optimizing for human or AI traffic. The research proposes architectural separations that could serve both without degrading either.