Cloudflare CEO: Google sees 3x more web content than OpenAI through crawler monopoly
Cloudflare data shows Googlebot accesses 3.2x more unique URLs than OpenAI and 4.8x more than Microsoft, as UK regulator considers crawler separation mandate.

Cloudflare data shows Googlebot accesses 3.2x more unique URLs than OpenAI and 4.8x more than Microsoft, as UK regulator considers crawler separation mandate.
Cloudflare CEO Matthew Prince announced yesterday that Google's search crawler accesses substantially more internet content than competing AI companies, creating what the executive characterizes as an unfair competitive advantage in artificial intelligence development. According to data from the networking infrastructure company, Googlebot successfully accessed individual pages almost two times more than ClaudeBot and GPTBot, three times more than Meta-ExternalAgent, and more than three times more than Bingbot over a two-month observation period.
The disclosure coincides with a consultation opened by the UK's Competition and Markets Authority examining conduct requirements for Google following its designation with Strategic Market Status in the search market. Cloudflare released these findings through both a social media post from Prince and a detailed blog post from policy executives Maria Palmieri and Sebastian Hufnagel published January 30.
We cannot have a fair market for AI when Google leverages their search monopoly to see 3.2x as much of the web as OpenAI, 4.8x as much as Microsoft, and more than 6x as much as nearly everyone else. Most data wins in AI. Google needs to play by the same rules as everyone else. https://t.co/5fNYpLtcTY
— Matthew Prince 🌥 (@eastdakota) January 30, 2026
"We cannot have a fair market for AI when Google leverages their search monopoly to see 3.2x as much of the web as OpenAI, 4.8x as much as Microsoft, and more than 6x as much as nearly everyone else," Prince wrote in a post that generated over 354,000 views within hours. "Most data wins in AI. Google needs to play by the same rules as everyone else."
The data reveals stark disparities in content access across major AI crawlers. Based on sampled unique URLs using Cloudflare's network over two months, Googlebot crawled approximately 8 percent of observed pages. In rounded multiple terms, Googlebot sees 1.70 times the unique URLs accessed by ClaudeBot, 1.76 times those seen by GPTBot, 2.99 times Meta-ExternalAgent's reach, and 3.26 times the pages crawled by Bingbot.
The gap widens dramatically for smaller AI crawlers. According to Cloudflare's measurements, Googlebot accessed 5.09 times more unique URLs than Amazonbot, 14.87 times more than Applebot, 23.73 times more than Bytespider, 166.98 times more than PerplexityBot, 714.48 times more than CCBot, and 1,801.97 times more than archive.org_bot.
These access differentials stem from publishers' dependence on Google Search for traffic and advertising revenue. Cloudflare data shows that almost no website explicitly disallows Googlebot in full through robots.txt files, reflecting the crawler's importance in driving human visitors to publisher content. This creates what the CMA describes as a situation where "publishers have no realistic option but to allow their content to be crawled for Google's general search because of the market power Google holds in general search."
The problem extends beyond simple access metrics. Google currently operates Googlebot as a dual-purpose crawler that simultaneously gathers content for traditional search indexing and for AI applications including AI Overviews and AI Mode. According to the CMA, this means "Google currently uses that content in both its search generative AI features and in its broader generative AI services."
Publishers cannot afford to block Googlebot without jeopardizing their appearance in search results, which remain critical for traffic generation and advertising monetization. This dependency forces publishers to accept that their content will be used in generative AI applications that return minimal traffic to their websites, undermining the business models that have sustained digital publishing.
When comparing crawler blocking patterns through Web Application Firewalls, Cloudflare found that websites actively blocking popular AI crawlers like GPTBot and ClaudeBot outnumbered those blocking Googlebot and Bingbot by nearly seven times between July 2025 and January 2026. Customers using Cloudflare's AI Crawl Control demonstrate clear preferences for maintaining Googlebot access while restricting other AI crawlers.
The CMA launched its consultation on proposed conduct requirements for Google on January 28, following the company's October 2025 designation with Strategic Market Status under the Digital Markets, Competition and Consumers Act 2024. The designation encompasses AI Overviews and AI Mode, granting the CMA authority to impose legally enforceable rules specifically relating to AI crawling behavior with significant sanctions for non-compliance.
According to the CMA's proposed requirements, Google would need to grant publishers "meaningful and effective" control over whether their content is used for AI features. The regulator would prohibit Google from taking any action that negatively impacts the effectiveness of those control options, such as intentionally downranking content in search results.
Cloudflare executives argue the proposed remedies remain insufficient. "The most effective way to give publishers that necessary control is to require Googlebot to be split up into separate crawlers," according to the blog post. "That way, publishers could allow crawling for traditional search indexing, which they need to attract traffic to their sites, but block access for unwanted use of their content in generative AI services and features."
The company characterizes Google's dual-purpose crawler as non-compliant with responsible AI bot principles requiring distinct purpose declaration. Unlike competitors such as OpenAI and Anthropic, which operate separate crawlers for different functions, Google combines multiple purposes through a single bot identifier.
Google maintains nearly 20 other specialized crawlers for various purposes including image data, video data, and cloud services. Cloudflare argues this demonstrates the technical feasibility of crawler separation. "Requiring Google to split up Googlebot by purpose — just like Google already does for its nearly 20 other crawlers — is not only technically feasible, but also a necessary and proportionate remedy," according to the company's position.
The CMA considered crawler separation as an "equally effective intervention" but ultimately rejected mandating separation based on Google's input characterizing the requirement as overly burdensome. The regulator instead proposed requiring Google to develop new proprietary opt-out mechanisms tied specifically to the Google platform.
Cloudflare received feedback from customers indicating that Google's current proprietary opt-out mechanisms, including Google-Extended and 'nosnippet', have failed to prevent content utilization in ways publishers cannot control. These tools do not enable mechanisms for fair compensation, according to the company's consultation response.
The proposed conduct requirements would mandate increased transparency from Google, requiring publication of clear documentation on how crawled content is used for generative AI and exactly what various publisher controls cover in practice. Google would need to ensure effective attribution of publisher content and provide detailed, disaggregated engagement data including specific metrics for impressions, clicks, and click quality.
However, Cloudflare characterizes this framework as creating "a state of permanent dependency" where publishers must use Google's proprietary mechanisms under conditions set by Google rather than exercising direct, autonomous control. "A framework where the platform dictates the rules, manages the technical controls, and defines the scope of application does not offer 'effective control' to content creators or encourage competitive innovation in the market," according to the blog post.
The company argues that creating new opt-out controls makes it impossible for publishers to use external tools to block Googlebot from accessing their content without jeopardizing search visibility. Publishers would still have to allow Googlebot to scrape their websites, with limited visibility available if Google does not respect their signaled preferences and no enforcement mechanisms to deploy independently.
Major publishers have expressed support for crawler separation requirements. The Daily Mail Group, The Guardian, and the News Media Association provided public backing for mandatory crawler separation as a remedy, according to Cloudflare's documentation.
The competitive implications extend beyond publisher control. Cloudflare CEO Matthew Prince stated in July 2025 that the company would obtain methods from Google to block AI Overviews and Answer Boxes while preserving traditional search indexing capabilities. "We will get Google to provide ways to block Answer Box and AI Overview, without blocking classic search indexing, as well," Prince declared at the time, expressing confidence about securing concessions from the search giant.
The timing of Cloudflare's data release coincides with mounting regulatory pressure on Google's AI features. Research documented throughout 2025 indicates that AI-driven search summaries reduce publisher traffic by 20-60 percent on average, with niche sites experiencing losses up to 90 percent. The Interactive Advertising Bureau Technology Laboratory formed its Content Monetization Protocols working group in August 2025 specifically to address these challenges.
Google Network advertising revenue declined 1 percent to $7.4 billion in the second quarter of 2025, indicating reduced monetization opportunities for AdSense, AdMob, and Google Ad Manager participants as AI features increasingly satisfy user intent without requiring website visits.
The CMA's designation considers future competitive dynamics over a five-year horizon. The regulator examined whether Microsoft Bing, DuckDuckGo, and other search engines provide sufficient competitive pressure, finding that Google's default agreements across major access points contribute to maintaining its market position. Data showed Google pays billions annually for default search placement.
Cloudflare operates as a major infrastructure provider serving millions of websites globally, positioning the company with visibility into crawler behavior patterns across substantial portions of the internet. The networking company launched pay-per-crawl services in July 2025, allowing content creators to charge AI crawlers for access using HTTP 402 Payment Required responses.
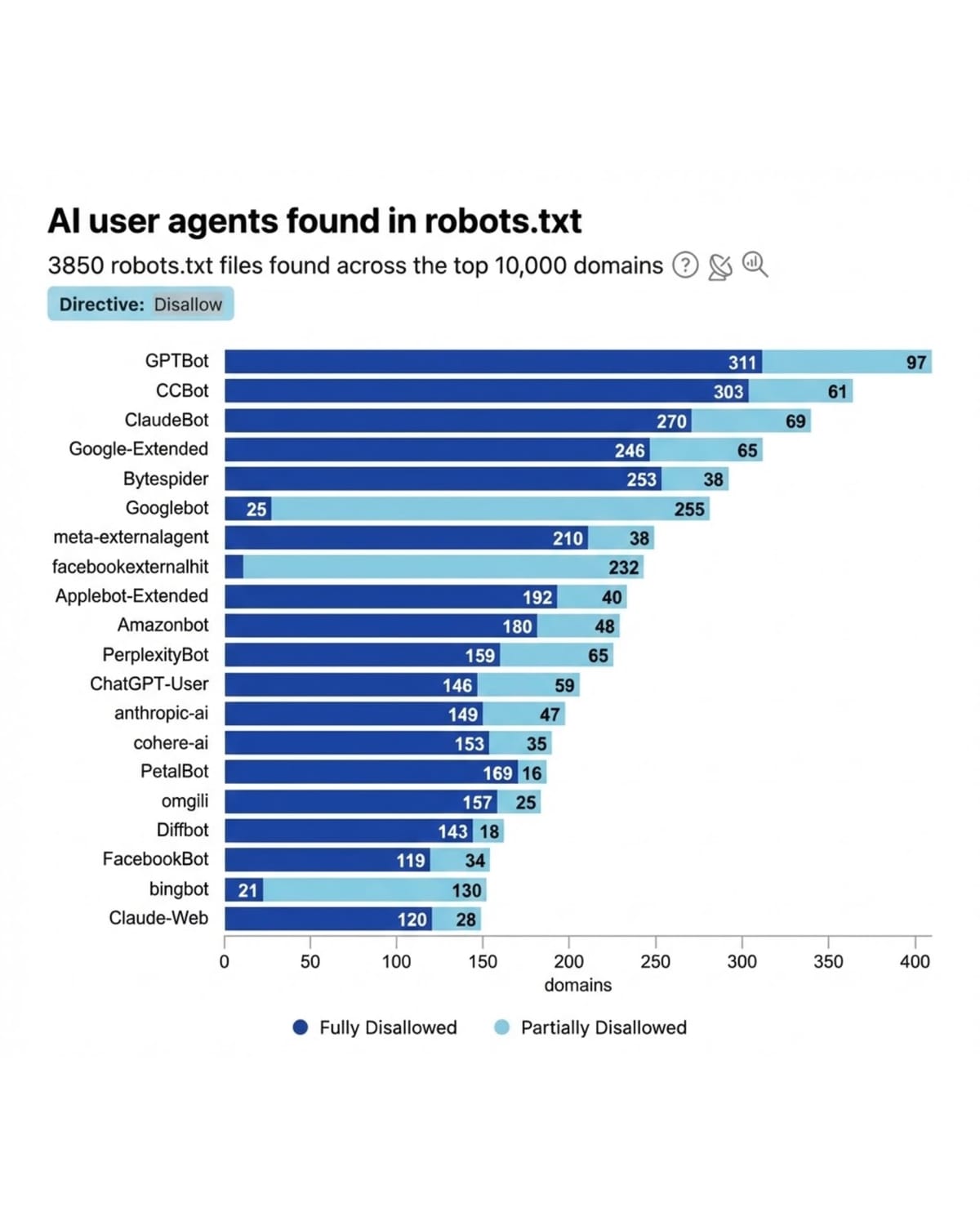
The technical implementation details matter for website operators. Robots.txt files allow expression of crawling preferences but rely on voluntary compliance from crawlers. Publishers seeking more effective control can configure Web Application Firewalls with specific rules to technically prevent undesired crawlers from accessing sites regardless of bot compliance.
According to Cloudflare analysis of robots.txt files found across the top 10,000 domains, AI user agents show varying disallow rates. The data reveals differentiated blocking patterns where publishers distinguish between crawlers they consider essential versus those they view as optional or problematic.
The crawler access disparities documented by Cloudflare validate concerns about Google's competitive advantages in AI development. Unlike other AI companies, Google can use its search crawler to gather data for multiple AI functions with minimal fear that access will be restricted, according to the CMA analysis. The regulator recognizes that this prevents emergence of a well-functioning marketplace where AI developers negotiate fair value for content.
Other AI companies face structural disadvantages in a system allowing one dominant player to bypass compensation entirely. As the CMA states, "[b]y not providing sufficient control over how this content is used, Google can limit the ability of publishers to monetise their content, while accessing content for AI-generated results in a way that its competitors cannot match."
The consultation process allows stakeholders to provide evidence and arguments before the CMA imposes final conduct requirements. Cloudflare emphasized its commitment to engaging with the CMA and other partners during consultations to provide evidence-based data helping shape final decisions on conduct requirements that are targeted, proportional, and effective.
British regulators maintain authority to impose financial penalties for non-compliance with designated conduct requirements, with potential fines reaching significant percentages of annual worldwide group turnover. The Digital Markets, Competition and Consumers Act 2024 grants the CMA expanded powers to directly determine violations and impose remedies without court proceedings.
The crawler separation debate occurs against broader antitrust enforcement targeting Google's business practices. A Virginia federal court ruled in April 2025 that the company holds an illegal monopoly in online advertising technology markets. The European Union designated Google as a "gatekeeper" under the Digital Markets Act for both search and advertising services. A U.S. District Court ruled in August 2024 that Google had monopoly power in general search and search text advertising.
Cloudflare's analysis extends to enforcement patterns beyond robots.txt files. The company's AI Crawl Control feature, integrated into its Application Security suite, shows that websites block other popular AI crawlers far more frequently than Googlebot and Bingbot. This seven-to-one ratio reflects Googlebot's unique position as both an AI crawler and the gateway to search visibility.
The networking infrastructure company argues that mandatory crawler separation benefits AI companies by leveling the playing field, in addition to giving publishers more control over content. "Mandatory crawler separation is not a disadvantage to Google, nor does it undermine investment in AI," according to Cloudflare's position. "On the contrary, it is a pro-competitive safeguard that prevents Google from leveraging its search monopoly to gain an unfair advantage in the AI market."
Industry observers note the implications for innovation in AI development. If one company maintains vastly superior access to internet content through search market dominance, that advantage compounds over time as AI models require extensive data for training and inference operations. The quality and breadth of training data directly influences model capabilities and competitive positioning.
The CMA's consultation represents the first deployment of conduct requirements under the digital markets competition regime in the UK. Final requirements imposed by the regulator become legally enforceable rules with significant sanctions ensuring compliance. The process marks a significant legal shift from relying on antitrust investigations to imposing targeted interventions when firms hold substantial, entrenched market power.
Google's response to the CMA emphasized the company's contributions to UK businesses and consumers. Oliver Bethell, Google's Director of Competition, stated that Search helps millions of British businesses grow and reach customers in innovative ways, according to previous CMA documentation.
The implementation challenges extend beyond technical requirements. Enforcement of conduct requirements by the CMA, if done properly, will be very onerous without guarantee that publishers will trust the solution, according to Cloudflare's assessment. The company argues that a framework where publishers cannot prevent Google from accessing their data for particular purposes in the first place, but must instead rely on Google-managed workarounds after crawlers have already accessed content, fails to provide meaningful control.
Market dynamics support expectations of eventual cooperation between Google and content publishers on crawler separation. AI search visitors provide 4.4 times higher value than traditional organic traffic according to 2025 research, creating economic incentives for controlled access rather than complete blocking. This value differential suggests potential for negotiated solutions where publishers maintain some access while charging for AI usage.
The global regulatory landscape shows coordination across jurisdictions. The European Commission published its advertising technology antitrust decision against Google in September 2025, imposing a €2.95 billion fine for abusing dominant positions. Multiple enforcement actions across different markets create cumulative pressure on Google's business practices and competitive positioning.
Cloudflare positioned the UK consultation as a unique opportunity for global leadership in protecting content value. "The UK has a unique chance to lead the world in protecting the value of original and high-quality content on the Internet," according to the company's blog post. "However, we worry that the current proposals fall short."
The technical specifications matter for publishers evaluating their options. Crawler separation would enable granular control where publishers allow traditional search indexing while blocking AI training and inference applications. This specificity cannot be achieved through platform-managed opt-out mechanisms that operate after crawlers have already accessed content.
Prince's social media announcement generated substantial industry discussion, with responses ranging from technical implementation questions to broader debates about market structure and competition policy. Some commenters questioned whether crawler blocking would effectively address competitive imbalances, while others emphasized the importance of transparent control mechanisms.
The final CMA decision will establish precedent for how digital market regulators approach platform dominance intersecting with emerging technologies. Whether behavioral remedies requiring new opt-out mechanisms prove sufficient, or whether structural requirements mandating crawler separation become necessary, will influence regulatory approaches in other jurisdictions examining similar competitive concerns.
Who: Cloudflare CEO Matthew Prince and policy executives Maria Palmieri and Sebastian Hufnagel released data affecting Google, OpenAI, Microsoft, Meta, Amazon, Apple, ByteDance, Perplexity, and other AI companies, alongside publishers globally dependent on search traffic and the UK Competition and Markets Authority evaluating conduct requirements.
What: Cloudflare data reveals Googlebot accesses 1.70 times more unique URLs than ClaudeBot, 1.76 times more than GPTBot, 2.99 times more than Meta-ExternalAgent, and 3.26 times more than Bingbot over a two-month observation period, with gaps widening to 166.98 times more than PerplexityBot and 714.48 times more than CCBot. The company argues Google's dual-purpose crawler combining search indexing and AI applications creates unfair competitive advantages requiring mandatory crawler separation.
When: Cloudflare published findings January 30, 2026, two days after the CMA opened its consultation on proposed conduct requirements for Google following the company's September 30, 2025 designation with Strategic Market Status under the Digital Markets, Competition and Consumers Act 2024.
Where: The analysis applies globally across Cloudflare's network serving millions of websites, with immediate regulatory implications for the UK market under CMA jurisdiction and potential influence on European Union enforcement under the Digital Markets Act and U.S. antitrust proceedings addressing Google's search and advertising technology monopolization.
Why: Publishers cannot block Googlebot without losing search visibility and advertising revenue, forcing acceptance of content usage in AI applications that return minimal traffic while Google's competitors face systematic disadvantages accessing training and inference data. The competitive imbalance threatens fair AI market development and publisher economic sustainability as AI-driven search summaries reduce traditional traffic by 20-60 percent on average according to documented research.