Cloudflare today released an extensive analysis of AI bot activity across its network, shedding light on the scale and nature of AI-driven web crawling. The report, which comes alongside the introduction of a new feature to block AI bots, provides crucial insights into how AI companies are gathering data from websites across the internet.
According to Cloudflare's data, AI bots accessed approximately 39% of the top one million Internet properties using their services in June 2024. This statistic underscores the pervasive nature of AI crawlers and their significant impact on web traffic. Notably, only 2.98% of these properties had implemented measures to block or challenge such requests, indicating a potential gap in awareness or action against AI bot activity.
The analysis revealed a clear correlation between a website's popularity and its likelihood of being targeted by AI bots. Among the top 10 most visited websites on Cloudflare's network, 80% were accessed by AI bots, with 40% of these sites actively blocking such requests. This trend continued down the popularity rankings, with 63% of the top 100 sites accessed by AI bots and 16% blocking them. For the top million sites, the figures stood at 38.73% accessed and 2.98% blocking.
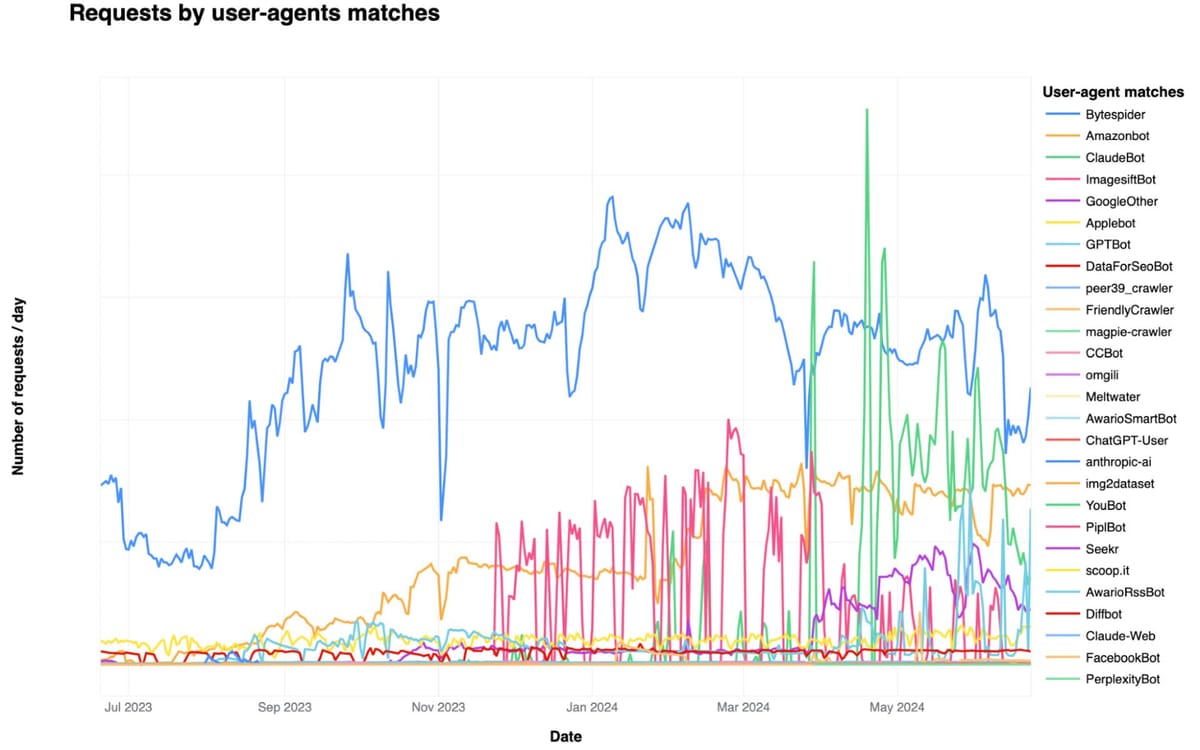
Bytespider, operated by ByteDance (the parent company of TikTok), emerged as the most active AI bot in terms of request volume. It is reportedly used to gather training data for large language models, including those supporting ByteDance's ChatGPT competitor, Doubao. Bytespider not only led in the number of requests but also in the extent of its Internet property crawling, accessing 40.40% of websites protected by Cloudflare.
Following Bytespider in request volume were Amazonbot and ClaudeBot. Amazonbot, believed to be used for indexing content for Alexa's question-answering capabilities, was the second most active in terms of requests. ClaudeBot, associated with training the Claude chatbot, has recently seen an increase in request volume.
GPTBot, managed by OpenAI, ranked high in both the extent of Internet property crawling and the frequency of being blocked by website operators. It accessed 35.46% of Cloudflare-protected websites, second only to Bytespider.
The report provided a detailed breakdown of the share of websites accessed by various AI bots:
- Bytespider: 40.40%
- GPTBot: 35.46%
- ClaudeBot: 11.17%
- ImagesiftBot: 8.75%
- CCBot: 2.14%
- ChatGPT-User: 1.84%
- omgili: 0.10%
- Diffbot: 0.08%
- Claude-Web: 0.04%
- PerplexityBot: 0.01%
Cloudflare's analysis also examined the most commonly actioned AI bots in robots.txt files across the top 10,000 Internet domains. Interestingly, while GPTBot, CCBot, and Google were frequently referenced in these files, popular AI crawlers like Bytespider and ClaudeBot were often not specifically disallowed.
The report highlighted the challenges in relying solely on robots.txt files for bot control. While some website operators use this method to block access to AI crawlers, its effectiveness depends on bot operators honestly identifying themselves and respecting the robots.txt directives. Cloudflare noted instances of bot operators attempting to appear as real browsers by using spoofed user agents, emphasizing the need for more sophisticated detection methods.
To illustrate this point, Cloudflare shared an example of how their machine learning models accurately identified a specific bot that was attempting to hide its activity. The company's global machine learning model consistently recognized this traffic as coming from a bot, assigning it a score below 30 on their bot scoring system, regardless of the user agent changes.
This capability is particularly important in light of recent allegations against some AI companies for using deceptive practices to scrape content. For instance, Perplexity AI was accused of impersonating legitimate visitors to gather data from websites. Cloudflare's system aims to detect such evasive tactics by leveraging its vast network, which processes an average of 57 million requests per second, to understand the trustworthiness of various bot fingerprints.
The company's approach to bot detection involves computing global aggregates across numerous signals. This method allows their models to flag traffic from evasive AI bots accurately without the need for manual fingerprinting. As a result, Cloudflare claims that customers using their service are protected from the newest waves of bot activity as soon as they emerge.
In response to these findings and ongoing concerns about unauthorized content use for AI training, Cloudflare announced a new feature allowing all customers, including those on the free tier, to block AI bots with a single click. This tool is designed to automatically update over time as Cloudflare identifies new fingerprints of bots engaged in widespread web scraping for model training.
The broader implications of this data extend beyond individual website protection. As the value of original content for AI training continues to rise, the activities of AI bots have become a contentious issue. The scale of AI bot activity revealed in this report highlights the potential impact on content creators and raises questions about data ownership, fair use, and compensation for content that contributes to AI advancements.
Furthermore, the discrepancy between the prevalence of AI bot activity and the relatively low rate of websites actively blocking such bots suggests a potential lack of awareness or resources among website operators to address this issue. This situation underscores the need for more accessible tools and information to help content creators protect their intellectual property.
The data also provides insights into the strategies employed by different AI companies in their data collection efforts. The varying levels of activity and targeting among different AI bots could reflect different approaches to model training and development, as well as differing policies regarding web crawling and data use.
As the AI industry continues to evolve rapidly, the findings from Cloudflare's report are likely to inform ongoing discussions about the ethical and practical considerations of web scraping for AI training. The report highlights the need for clearer regulations and industry standards regarding the use of web content for AI training, balancing the potential benefits of AI advancement with the rights and interests of content creators.
Share this article
The link has been copied!