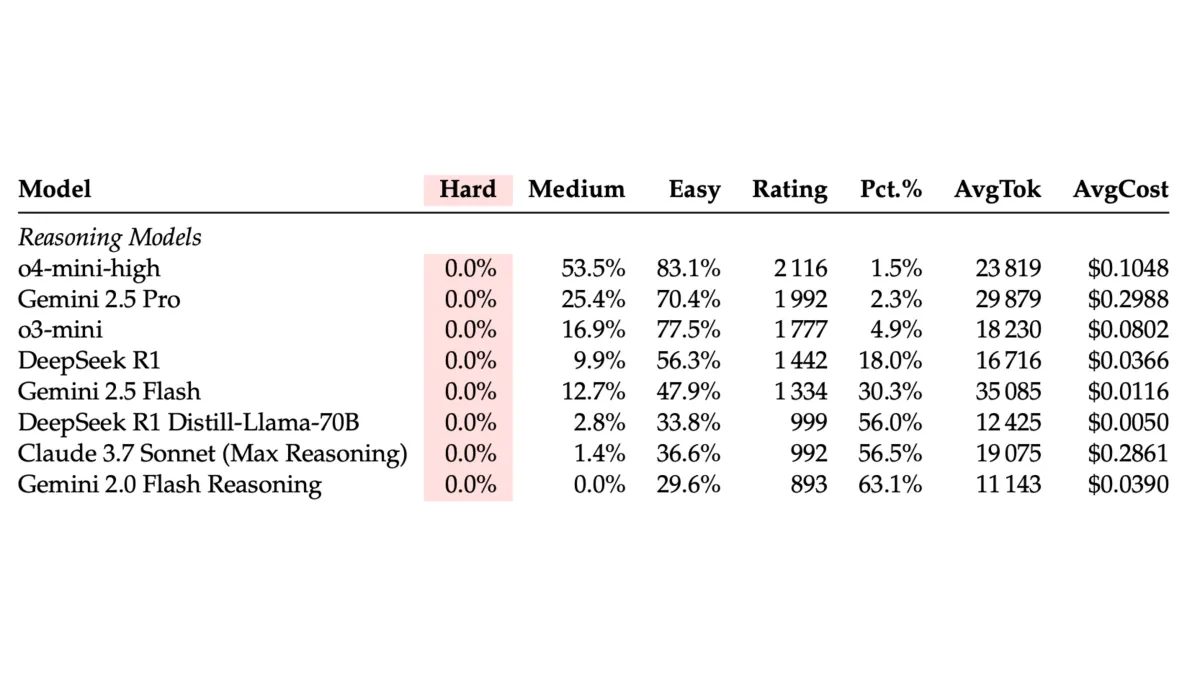
Researchers from eight universities released LiveCodeBench Pro on June 13, 2025, a comprehensive benchmark that challenges previous claims about AI superiority in competitive programming. The study shows frontier models achieve only 53% accuracy on medium-difficulty problems and 0% on hard problems without external tools.
The benchmark emerged from collaboration between researchers at New York University, Princeton University, University of California San Diego, and five other institutions. According to the research team, existing evaluations suffered from data contamination and failed to isolate genuine reasoning from memorization.
LiveCodeBench Pro contains 584 high-quality problems collected in real-time from premier contests including Codeforces, ICPC, and IOI before solutions appear online. Each problem receives annotation from competitive programming experts and international olympiad medalists who categorize problems by algorithmic skills and cognitive focus.
Sign up for PPC Land
Your go-to source for digital marketing news. Get the latest updates from Google, Meta, Amazon, and The Trade Desk. Stay informed on ad tech innovations, programmatic trends, and policy changes.
No spam. Unsubscribe anytime.
Summary
Who: Research team from eight universities led by competitive programming experts and international olympiad medalists
What: LiveCodeBench Pro benchmark reveals AI models achieve only 53% accuracy on medium programming problems and 0% on hard problems without external tools
When: Released June 13, 2025, following problem collection from November 2024 to April 2025
Where: Problems sourced from premier contests including Codeforces, ICPC series, and IOI series across global competitive programming platforms
Why: Existing evaluations suffered from data contamination and failed to distinguish genuine algorithmic reasoning from memorization, necessitating rigorous real-time benchmark
The research team evaluated frontier models including o4-mini-high, Gemini 2.5 Pro, o3-mini, and DeepSeek R1. Results show the best-performing model, o4-mini-high, achieved an Elo rating of 2116 without external tools - placing it in the 1.5% percentile among human competitors.
"Current models excel in more structured and knowledge-heavy problems that require more logical derivation than deduction, but they perform significantly worse on observation-heavy problems demanding observation and creativity," the researchers stated. Only problems involving combinatorics, segment trees, and dynamic programming saw o4-mini-high perform above grandmaster level.
The team categorized problems into three cognitive focus areas: knowledge-heavy (requiring established algorithms), logic-heavy (demanding step-by-step reasoning), and observation-heavy (needing creative insights). Models struggled most with observation-heavy categories like game theory and greedy algorithms.
Analysis of 125 failed submissions revealed conceptual errors dominate model failures while implementation remains a relative strength. The models frequently failed on provided sample inputs, suggesting incomplete utilization of given information.
LiveCodeBench Pro's real-time collection process captures problems at contest launch before accepted solutions, hints, or discussions appear online. This methodology addresses contamination concerns that plagued earlier benchmarks relying on static archives.
Sign up for PPC Land
Your go-to source for digital marketing news. Get the latest updates from Google, Meta, Amazon, and The Trade Desk. Stay informed on ad tech innovations, programmatic trends, and policy changes.
No spam. Unsubscribe anytime.
The study found reasoning models showed substantial improvements over non-reasoning counterparts, particularly in combinatorics where DeepSeek R1 gained nearly 1400 rating points over V3. However, reasoning brought minimal improvement for observation-heavy problems, raising questions about current chain-of-thought limitations.
Multiple attempts (pass@k) significantly improved performance, with o4-mini-medium's rating rising from 1793 at pass@1 to 2334 at pass@10. OpenAI's reported Codeforces rating of 2719 for o4-mini with terminal access and pass@k suggests remaining improvements stem from tool integration rather than pure reasoning capabilities.
The benchmark introduces difficulty tiers based on Codeforces ratings. Easy problems (≤2000 rating) require standard techniques solvable by world-class contestants in 15 minutes. Medium problems (2000-3000 rating) demand fusion of multiple algorithms with mathematical reasoning. Hard problems (>3000 rating) require masterful algorithmic theory and deep mathematical intuition that eludes 99.9% of participants.
Expert annotation revealed models excel in implementation-heavy segments tree and data structure problems but struggle with nuanced case analysis. Interactive problems exposed pronounced weaknesses, with o3-mini-high's rating collapsing to around 1500.
The research highlights a significant gap between aggregate performance metrics and granular analysis. While reported ratings suggest near-human performance, detailed examination reveals fundamental limitations in algorithmic reasoning and problem-solving creativity.
LiveCodeBench Pro operates as a continuously updated benchmark providing ongoing challenges for future models. The team designed the platform to offer fine-grained diagnostics steering improvements in code-centric LLM reasoning.
According to the study, high performance appears largely driven by implementation precision and tool augmentation rather than superior reasoning. The benchmark thus highlights the significant gap to human grandmaster levels while offering diagnostic tools for targeted improvements.
Get the PPC Land newsletter ✉️ for more like this
Subscribe
The release represents the latest attempt to establish rigorous evaluation standards for AI coding capabilities. As the marketing community increasingly integrates AI tools for development workflows, understanding genuine model limitations becomes crucial for informed adoption decisions.
Previous research revealed widespread corporate skepticism toward AI language models, with 80% of companies blocking LLM access to their websites. LiveCodeBench Pro's findings provide empirical justification for cautious approaches to AI integration in complex reasoning tasks.
The benchmark's methodology addresses concerns about evaluation reliability that affect other performance testing initiatives. Similar to how Speedometer 3.0 established new browser benchmarking standards, LiveCodeBench Pro aims to create definitive measures for AI coding capabilities.
Timeline
Share this article
The link has been copied!