Google Search Advocate John Mueller yesterday highlighted a testing capability that allows website owners to verify whether their pages exceed Googlebot's 2MB HTML fetch limit. The feature addition comes after Google reduced Googlebot's file size limit from 15MB to just 2MB earlier this year, marking an 86.7% decrease in crawling capacity.
Dave Smart, the developer behind Tame the Bots, implemented functionality on February 6 to cap text-based files to 2MB in his fetch and render simulator tool. The addition allows developers to test whether their HTML responses would be truncated when accessed by Google's crawler. "At the risk of overselling how much of a real world issue this is (it really isn't for 99.99% of sites I'd imagine), I added functionality to tamethebots.com/tools/fetch-... to cap text based files to 2 MB to simulate this," Smart stated in his Bluesky announcement.
Mueller's acknowledgment of the tool arrived within hours. "If you're curious about the 2MB Googlebot HTML fetch limit, here's a way to check," the Google Switzerland-based search advocate wrote at 12:48 on February 6. His endorsement provides official validation for a testing methodology addressing technical concerns that emerged following Google's documentation changes.
Technical implementation details
The Tame the Bots fetch and render simulator operates through multiple configuration options designed to replicate Googlebot's crawling behavior. The tool processes requests using the Google open source parser for robots.txt files, fetching these files fresh for each test to ensure accurate compliance checking. According to the tool's documentation, it honors robots.txt directives using the same parsing logic Google employs.
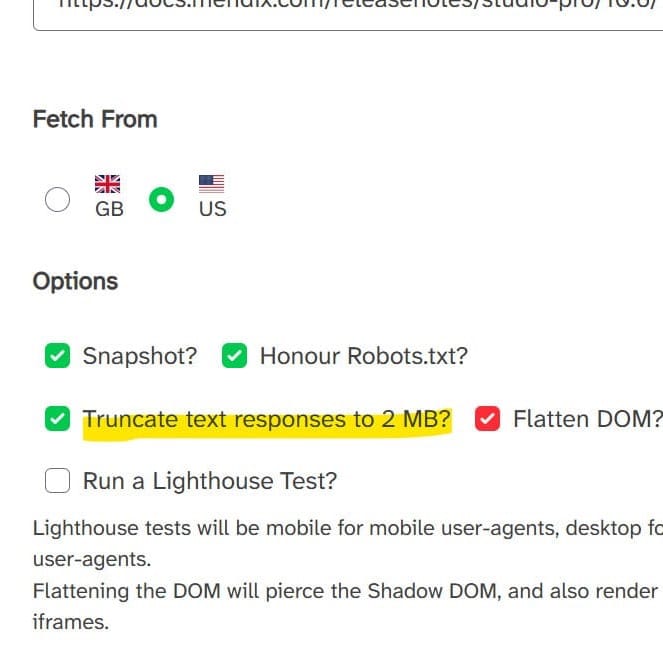
The new 2MB truncation feature appears as an optional checkbox within the tool's interface alongside existing capabilities including snapshot generation, robots.txt compliance, DOM flattening, and Lighthouse testing. When enabled, the truncation simulates Google's current maximum file size limit for initial HTML responses. Users can fetch from either UK or US geographic locations and select various user agents including Googlebot Mobile to test different crawling scenarios.
The rendering process employs Puppeteer for JavaScript execution and dom2html for DOM flattening. Snapshot strategy options allow users to control when the tool captures rendered HTML, with the default waiting for two network connections to become idle before finalizing the snapshot. The tool returns both rendered HTML and initial source code, along with screenshots showing how pages appear to Googlebot.
Smart emphasized the tool's limitations in achieving perfect parity with Google's systems. "Although intended to match, parity with the Google WRS cannot be guaranteed, always confirm in either the Rich Results Test or URL Inspection tool in Search Console," the tool's documentation states. Test results get deleted after five minutes maximum and are not logged, addressing privacy concerns for users testing live production sites.
Real-world implications assessed
Smart's characterization of the 2MB limit as affecting less than 0.01% of websites aligns with broader industry assessments about HTML file sizes. The developer noted in a subsequent post on February 3 that "2 MB of raw HTML is a BIG, like REALLY big file." His observation reflects the reality that most HTML documents measure far below this threshold.
The 2MB limit applies specifically to initial HTML responses rather than rendered content after JavaScript execution. This distinction matters for single-page applications and JavaScript-heavy websites where significant content gets generated client-side. As documented in Google's December JavaScript rendering clarification, pages returning 200 status codes consistently enter Google's rendering queue regardless of initial HTML size.
Smart implemented the testing feature as what he described as "a fun exercise" rather than an urgent industry need. "I would treat is as guidance if you are testing one of the few sites that genuinely does get affected by this limit," he explained. His pragmatic approach acknowledges that while the technical constraint exists, its practical impact remains limited.
The developer directed users to rely on Google's own verification tools for definitive answers. "As ever, what's actually indexed (URL inspector) & findable (site: and quote snippet) are the final word!" Smart stated. This guidance emphasizes that testing tools provide directional information while Search Console's URL Inspection tool delivers authoritative data about what Google actually crawled and indexed.
Context of crawling restrictions
The 2MB limit emerged as part of broader changes to Google's crawling infrastructure. Google updated its crawling documentation on November 20, 2025, adding HTTP caching support details and transfer protocol specifications. The infrastructure documentation now includes explicit information about HTTP/1.1 as the default protocol version and support for gzip, deflate, and Brotli compression methods.
Chris Long, co-founder at Nectiv, brought attention to the 2MB documentation change through social media discussions that spread across LinkedIn. Industry professionals including Barry Schwartz, Jamie Indigo, and Steve Toth participated in conversations about potential implementation impacts. The widespread discussion among technical SEO practitioners reflected uncertainty about how the reduced limit might affect crawling patterns and indexing behavior.
The distinction between compressed and uncompressed data creates implementation complexity. While developers typically serve compressed assets using gzip or brotli encoding, Googlebot applies the 2MB limit to decompressed content. This means pages delivering 500KB of compressed HTML could potentially exceed the limit if uncompressed size approaches 2MB, though such compression ratios would be unusual for text-based content.
JavaScript and CSS resources face particular scrutiny under the file size constraints. Single-page applications that compile large JavaScript bundles risk having execution interrupted if primary application code exceeds 2MB when decompressed. Modern web development practices often produce JavaScript bundles in the 500KB to 1.5MB range after compression, but uncompressed sizes can reach several megabytes for complex applications.
Integration with rendering infrastructure
The 2MB limit intersects with Google's Web Rendering Service operations documented on December 3, 2024. The rendering infrastructure operates through three distinct phases: crawling, rendering, and indexing. When Googlebot fetches a URL from its crawling queue, it first verifies whether robots.txt permits access. Pages passing this verification receive HTTP requests, and Google parses the HTML response to discover additional URLs through link elements.
For JavaScript-heavy sites, the rendering phase becomes critical. Pages returning 200 status codes consistently enter the rendering queue, where Google's headless Chromium executes JavaScript and generates rendered HTML. If primary application JavaScript exceeds the 2MB limit, the rendering process may work with incomplete code, potentially affecting the final indexed version.
The Web Rendering Service implements a 30-day caching system for JavaScript and CSS resources, independent of HTTP caching directives. This caching approach helps preserve crawl budget, which represents the number of URLs Googlebot can and wants to crawl from a website. The interaction between file size limits and resource caching creates complexity for developers managing deployment pipelines and cache invalidation strategies.
Content fingerprinting emerges as an important technique for managing JavaScript resource caching under these constraints. Including content hashes in filenames, such as "main.2bb85551.js," ensures that code updates generate different filenames that bypass stale caches while keeping individual file sizes manageable through code splitting techniques.
Crawl budget optimization context
The file size reduction may reflect Google's response to operational cost pressures. Cloudflare data revealed that Googlebot accesses substantially more internet content than competing crawlers. Based on sampled unique URLs using Cloudflare's network over two months, Googlebot crawled approximately 8 percent of observed pages, accessing 3.2 times more unique URLs than OpenAI's GPTBot and 4.8 times more than Microsoft's Bingbot.
Google currently operates Googlebot as a dual-purpose crawler that simultaneously gathers content for traditional search indexing and for AI applications including AI Overviews and AI Mode. Publishers cannot afford to block Googlebot without jeopardizing their appearance in search results, which remain critical for traffic generation and advertising monetization. The crawl limit reduction may enable Google to maintain comprehensive web coverage while reducing operational costs through stricter efficiency controls.
Google's crawling infrastructure has undergone continuous refinement addressing scale and efficiency concerns. The company deprecated the Crawl Rate Limiter Tool in Search Console on January 8, 2024, replacing it with automatic systems that adjust crawl rates based on server responses. If servers consistently return HTTP 500 status codes or response times increase significantly, Googlebot automatically slows crawling without requiring manual intervention.
Crawl rate disruptions affected multiple hosting platforms starting August 8, 2025, when large websites across Vercel, WP Engine, and Fastly infrastructures experienced dramatic decreases. Google acknowledged on August 28 that the issue stemmed from their systems, with John Mueller confirming the problem involved "reduced / fluctuating crawling from our side, for some sites." The incidents demonstrated Google's ongoing challenges in balancing comprehensive coverage with operational constraints.
Developer testing workflows
The Tame the Bots tool integrates into existing technical SEO workflows where developers verify crawler compatibility before deploying major changes. The fetch and render simulator has offered Chrome extension integration, allowing users to access testing capabilities through right-click context menus. The extension, available through the Chrome Store, provides quick access without requiring manual URL entry through the web interface.
Testing workflows typically involve multiple verification steps. Developers first check whether pages honor robots.txt directives correctly, then verify rendered HTML matches expectations, and finally confirm that critical resources load within crawler constraints. The 2MB truncation option adds another checkpoint to this process, allowing teams to identify potential issues before Google encounters them in production.
The tool's Lighthouse integration offers performance testing alongside crawlability verification. Lighthouse tests run as mobile for mobile user-agents and desktop for desktop user-agents, matching the responsive testing approach that mirrors actual user experiences. This combined testing approach helps developers identify both crawler-specific issues and broader performance problems that might affect user engagement metrics.
DOM flattening capabilities prove particularly valuable for testing complex JavaScript applications. The feature pierces the Shadow DOM and renders content from iframes, providing visibility into content that might be hidden from standard HTML parsing. This technique, inspired by discussions with Glenn Gabe of G-Squared Interactive, helps identify crawlability issues in modern web frameworks that rely heavily on component encapsulation.
Industry response patterns
Mueller's endorsement of the testing tool follows his broader pattern of engaging with community-developed resources that help website owners understand Google's requirements. The search advocate has warned against various optimization approaches while simultaneously encouraging developers to build tools and test technical implementations. On December 19, 2025, Mueller endorsed criticism of formulaic SEO content, sharing an article describing most optimization-focused content as "digital mulch."
The testing tool discussion occurs against backdrop of broader technical SEO tool evolution. Screaming Frog released version 22.0 with semantic similarity analysis on June 11, 2025, utilizing large language model embeddings to identify duplicate and off-topic content. Traditional SEO tools are adapting to AI-powered content analysis rather than becoming obsolete as some predicted.
Mueller has consistently emphasized that problematic technical implementations typically reveal themselves through normal browsing rather than requiring specialized detection tools. On February 3, 2026, Mueller cautioned against excessive redirect chain analysis, stating that issues significant enough to affect search rankings would manifest as user-facing problems. His approach prioritizes fixes for issues that impact actual users over optimization of edge cases that exist primarily in technical audits.
The file size testing capability aligns with Mueller's framework for useful technical tools: those that help developers identify real problems rather than creating work based on theoretical concerns. Smart's implementation includes the nuance that most sites won't encounter issues, avoiding the alarmist framing that sometimes accompanies technical SEO tool releases.
Verification best practices
Smart's guidance emphasizes that the tool provides approximations rather than guarantees. Website owners concerned about the 2MB limit should supplement testing tool results with verification through Google's official channels. Search Console's URL Inspection tool remains the authoritative source for understanding what Google actually crawled, rendered, and indexed from specific pages.
The URL Inspection tool shows whether Googlebot successfully fetched a page, whether it was allowed by robots.txt, what HTTP status code the server returned, whether rendering succeeded, and what the final indexed version looks like. For pages approaching the 2MB threshold, comparing the "View crawled page" output against source HTML can reveal whether truncation occurred.
Site-specific search queries using the site: operator provide additional verification of indexing status. Smart noted that pages visible only in targeted site: queries won't appear for average users, suggesting that partial indexing of truncated content may have minimal practical impact on search visibility. This observation aligns with Google's broader approach where multiple signals determine whether content deserves prominent placement in search results.
The testing tool's five-minute data retention policy addresses privacy concerns while providing sufficient time for users to review results. For organizations testing sensitive pre-production pages or internal applications, this automatic deletion ensures that test data doesn't persist in external systems where it might be accessed inappropriately.
Developers managing large HTML responses have several optimization approaches available beyond simple content reduction. Server-side rendering frameworks can generate minimal initial HTML that includes only critical above-the-fold content, deferring remaining page content to client-side JavaScript execution after initial page load. This pattern keeps initial HTML responses small while still delivering full functionality to end users.
Progressive enhancement techniques allow websites to deliver functional experiences with minimal HTML, then enhance with JavaScript for users whose browsers support advanced features. This approach naturally produces smaller initial HTML payloads while ensuring content remains accessible to crawlers that may execute JavaScript differently than modern browsers.
Code splitting divides JavaScript applications into smaller chunks that load on demand rather than delivering entire applications in single bundles. Modern build tools including Webpack, Rollup, and Vite provide sophisticated code-splitting capabilities that can keep individual file sizes well below the 2MB threshold while maintaining application functionality. Dynamic imports enable loading additional code only when specific features are accessed.
HTTP/2 server push capabilities allow delivering multiple resources in response to single requests, potentially working around certain file size constraints. However, Google's crawling infrastructure documentation indicates HTTP/1.1 remains the default protocol, suggesting developers shouldn't rely exclusively on HTTP/2 features for Googlebot optimization.
Regulatory and competitive context
The crawling limit reduction emerged during a period of heightened regulatory scrutiny over Google's data gathering practices. The UK's Competition and Markets Authority opened consultations examining conduct requirements for Google following its designation with Strategic Market Status. The CMA's investigation focuses on whether publishers have realistic options to prevent content usage in AI features while maintaining search visibility.
Publishers have expressed frustration that blocking AI features through existing mechanisms simultaneously eliminates visibility in conventional search results. The coupling of traditional search access with AI feature participation creates what industry observers characterize as forced participation. Cloudflare CEO Matthew Prince stated in July 2025 that the company would obtain methods from Google to block AI Overviews and Answer Boxes while preserving traditional search indexing capabilities.
The crawl limit reduction allows Google to maintain comprehensive web coverage essential for both search and AI applications while potentially reducing the operational costs that regulatory scrutiny has highlighted. By optimizing crawl efficiency through stricter file size limits, Google addresses cost concerns without fundamentally altering its access to publisher content.
Independent publishers filed a formal antitrust complaint with the European Commission on June 30, 2025, alleging abuse of market power through AI Overviews that display content summaries without generating clicks to original sources. The complaint argues that Google leverages its search dominance to extract publisher content for AI applications without fair compensation.
Future monitoring implications
Smart plans to treat the 2MB truncation feature as guidance for the small number of sites that might encounter issues rather than as a critical testing requirement for all implementations. "Mostly I did this as a fun exercise, & it is perhaps a bit blunt," he explained. This framing acknowledges the tool's limitations while providing useful functionality for edge cases.
The availability of testing tools allows developers to proactively identify potential issues rather than discovering problems after Google's systems encounter them in production. For organizations deploying content management systems, e-commerce platforms, or applications that generate large HTML responses, periodic testing provides early warning of crawling compatibility problems.
Monitoring crawl statistics through Search Console helps identify whether file size issues are affecting actual crawling behavior. Significant increases in crawl errors, declining crawl rates, or pages showing "Indexed, though blocked by robots.txt" status may indicate underlying technical problems worth investigating. The URL Inspection tool's detailed crawl information helps diagnose whether file size constraints contributed to indexing issues.
The interaction between file size limits, rendering infrastructure, and crawl budget allocation will likely continue evolving as Google refines its systems. Website owners should monitor official documentation updates and Search Console notifications for changes that might affect their specific implementations. Mueller's willingness to highlight community tools suggests Google recognizes value in third-party verification resources that help developers understand crawler behavior.
Timeline
- December 3, 2024: Google publishes detailed documentation explaining Googlebot's crawling process, including Web Rendering Service operations and 30-day caching for JavaScript resources
- November 20, 2025: Google updates crawling infrastructure documentation with HTTP caching support details and transfer protocol specifications
- December 18, 2025: Google clarifies JavaScript rendering for error pages, explaining how non-200 status codes may skip rendering phase
- Early 2026: Google reduces Googlebot file size limit from 15MB to 2MB, marking 86.7% decrease affecting uncompressed HTML, JavaScript, and CSS files
- February 3, 2026: Dave Smart posts on Bluesky stating "the max HTML size for the initial HTML is 2 MB, not 15 MB" and noting that "2 MB of raw HTML is a BIG, like REALLY big file"
- February 6, 2026: Dave Smart implements 2MB truncation feature in Tame the Bots fetch and render simulator at 12:30
- February 6, 2026: John Mueller endorses testing tool on Bluesky at 12:48, stating "If you're curious about the 2MB Googlebot HTML fetch limit, here's a way to check"
Summary
Who: Dave Smart, developer of Tame the Bots technical SEO tools, implemented the 2MB testing feature with endorsement from John Mueller, Google's Search Advocate based in Switzerland.
What: Smart added functionality to his fetch and render simulator tool allowing developers to cap text-based files to 2MB, simulating Google's current Googlebot HTML fetch limit. The tool provides optional truncation alongside existing features including robots.txt compliance testing, DOM flattening, and Lighthouse performance analysis.
When: Smart announced the feature implementation on February 6, 2026, at 12:30, with Mueller highlighting the testing capability approximately 18 minutes later at 12:48.
Where: The testing tool operates at tamethebots.com/tools/fetch-and-render as part of a broader suite of technical SEO verification resources. The tool processes requests from UK or US geographic locations using various Googlebot user agents.
Why: The testing capability addresses uncertainty following Google's reduction of its file size limit from 15MB to 2MB earlier in 2026, an 86.7% decrease that raised questions about potential crawling impacts. Smart characterized the real-world impact as affecting less than 0.01% of websites while acknowledging value in providing verification tools for edge cases. Mueller's endorsement validates the testing methodology for developers seeking to verify compatibility with Google's current crawling infrastructure.
Share this article
The link has been copied!