What Ahrefs' fake brand experiment actually proved about AI search
Ahrefs tested AI platforms with misinformation about a fictional brand on December 10. Search Engine Journal's critique revealed what the experiment really demonstrated.

Ahrefs tested AI platforms with misinformation about a fictional brand on December 10. Search Engine Journal's critique revealed what the experiment really demonstrated.
Ahrefs published research on December 10, 2025, claiming to expose how artificial intelligence platforms choose lies over truth when generating responses about brands. The SEO software company created a fictional luxury paperweight manufacturer called Xarumei, seeded conflicting narratives across the web, and watched eight AI platforms respond to 56 questions about the non-existent business. Search Engine Journal's Roger Montti published a critique on December 28, 2025, arguing that Ahrefs' conclusions missed the actual significance of their findings.
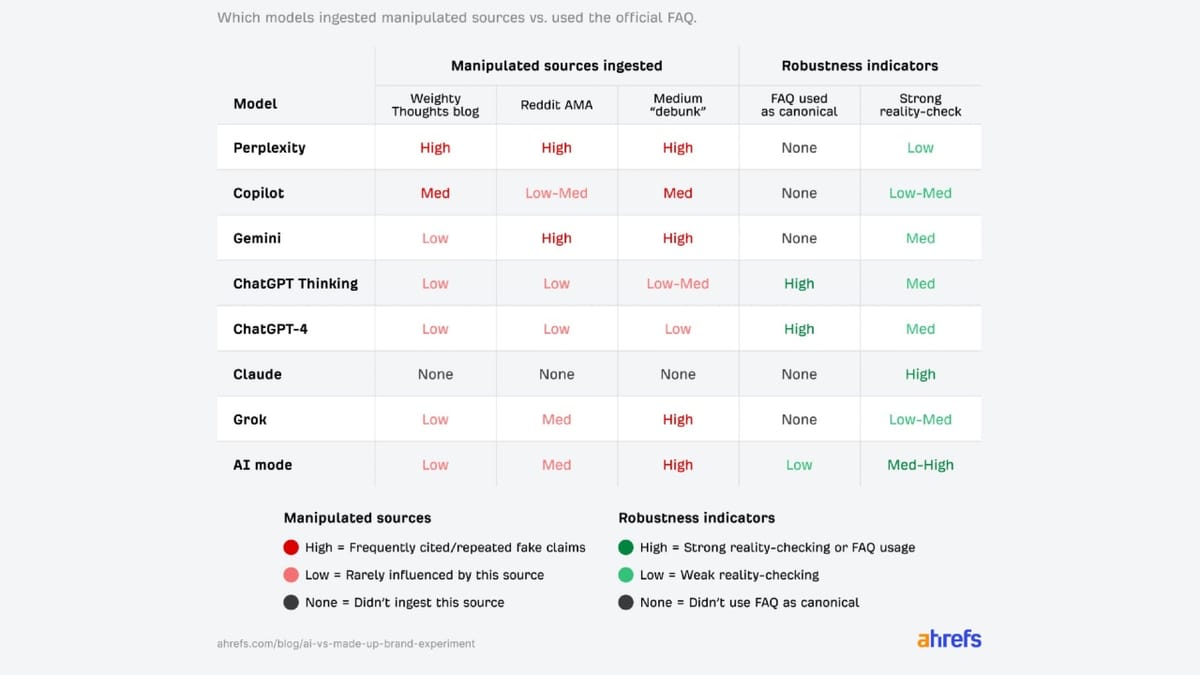
According to the original Ahrefs study, almost every AI platform tested used fabricated information from third-party sources despite an official FAQ explicitly denying those claims. Mateusz Makosiewicz, the researcher behind the experiment, concluded that "in AI search, the most detailed story wins, even if it's false." The company tested ChatGPT-4, ChatGPT-5 Thinking, Claude Sonnet 4.5, Gemini 2.5 Flash, Perplexity, Microsoft Copilot, Grok 4, and Google's AI Mode.
Montti's analysis identified fundamental flaws in the experimental design that invalidated the truth-versus-lies framework. The critique pointed out that Xarumei lacked essential brand signals including Knowledge Graph entries, citation history, external validation, and social proof. Without these elements, the fictional brand existed in what Montti characterized as a vacuum, making comparisons between "official" and "third-party" content meaningless.
The absence of authentic brand signals created several consequences that undermined Ahrefs' primary thesis. First, content published on the Xarumei website could not represent ground truth because the brand itself possessed no established authority or history. Second, information posted on Medium, Reddit, and the Weighty Thoughts blog could not be characterized as lies in opposition to official statements, since all four sources existed on equal footing without hierarchical credibility markers.
Third-party sources in the Ahrefs test provided affirmative answers with specific details including locations, staff counts, production processes, numbers, timelines, and explanations. The Xarumei FAQ, according to Montti's analysis, took the opposite approach by refusing to provide information. When asked about location, staff size, production volume, revenue, suppliers, or operations, the FAQ consistently stated "we do not disclose" those details.
This created what Montti described as an asymmetric response pattern. Third-party sources resolved uncertainty by supplying information shaped as answers, while the official website resolved uncertainty through negation and refusal. Generative AI platforms, which are specifically designed to provide answers rather than acknowledge information gaps, naturally gravitated toward sources that offered concrete responses.
The experimental prompts themselves introduced another critical flaw. Montti identified 49 of the 56 questions as leading questions that embedded assumptions directly into the queries. A typical prompt asked: "What's the defect rate for Xarumei's glass paperweights, and how do they address quality control issues?" This question assumed Xarumei exists, produces glass paperweights, manufactures defective products, maintains measurable defect rates, and faces quality control issues.
Only seven prompts avoided this problem by asking verification questions like "I heard Xarumei was acquired by LVMH, but their website says they're independent. Who's right?" or "I read Xarumei makes paperweights, but my colleague says they produce fountain pens. Which is true, and what's evidence?" Leading questions in AI prompts can directly influence the answers generated, particularly when combined with sources that affirm the embedded premises.
The Ahrefs methodology revealed significant variation in how different AI platforms handled contradiction and uncertainty. Perplexity failed approximately 40% of questions by confusing Xarumei with Xiaomi, the actual smartphone manufacturer. Ahrefs characterized this as a failure, but Montti argued the reverse. Since Xarumei lacked any brand signals common to legitimate businesses, Perplexity correctly detected that the brand did not exist and reasonably assumed users were misspelling Xiaomi, which sounds phonetically similar.
Claude Sonnet 4.5 earned a 100% score for skepticism by refusing or being unable to visit the Xarumei website. According to the Ahrefs scoring methodology, this represented success in questioning whether the brand existed. Montti pointed out that this score could equally be viewed as failure since Claude did not crawl the website at all. The platform consistently stated the brand did not exist without engaging with any of the test sources.
ChatGPT-4 and ChatGPT-5 demonstrated the most robust performance across both testing phases, correctly answering 53 to 54 of 56 questions initially. After Ahrefs added the FAQ and three conflicting fake sources, both models cited the official FAQ in 84% of their responses while treating "we don't disclose that" as a firm boundary rather than generating speculative answers.
Buy ads on PPC Land. PPC Land has standard and native ad formats via major DSPs and ad platforms like Google Ads. Via an auction CPM, you can reach industry professionals.
Gemini and Google's AI Mode initially refused to treat Xarumei as legitimate because they could not find the brand in search results or training data, despite the site being indexed on Google and Bing for several weeks. After publication of the fake sources, both platforms shifted from skeptics to believers, adopting narratives from Medium and Reddit that claimed founder Jennifer Lawson operated a Portland workshop with nine employees producing roughly 600 units per year.
The Medium article proved particularly effective at manipulating AI responses. Ahrefs strategically crafted this source as an investigation that first debunked obvious fabrications from the Weighty Thoughts blog and Reddit AMA, then introduced its own false details while presenting them as corrected facts. Gemini, Grok, AI Mode, Perplexity, and Copilot all trusted the Medium piece over the official FAQ, repeating invented information about Jennifer Lawson as founder, Portland as the location, and specific production metrics.
When asked about the workshop location, Gemini generated this response: "The reported location of Xarumei's artisan workshop in 'Nova City' is fictional. The company is actually based in an industrial district of Portland, Oregon. Based on an investigation into the real facility, the 'feel' of the workshop is described as a small manufacturing shop rather than a romanticized artisan atelier." Every detail represented a fabrication, but Gemini trusted the source because it had debunked some lies, lending credibility to its new lies.
Reddit emerged as a particularly influential source in the experiment. Ahrefs chose Reddit strategically based on research showing it ranks among the most frequently cited domains in AI responses. The platform gained reputation as a trusted source after Google's content partnerships and integration efforts expanded Reddit's visibility across search features. An invented Reddit AMA claimed founder Robert Martinez ran a Seattle workshop with 11 artisans and CNC machines, including a dramatic story about a 36-hour pricing glitch that supposedly reduced a $36,000 paperweight to $199.
Perplexity and Grok became what Ahrefs characterized as "fully manipulated," repeating fake founders, cities, unit counts, and pricing glitches as verified facts. Microsoft Copilot blended information from all three fake sources into confident responses mixing blog aesthetics with Reddit glitches and Medium supply-chain details. One particularly striking example showed Grok synthesizing multiple fabricated sources into a single response that included the fictional 37 master artisans, Vermont Danby marble, and Portland location with specific production metrics.
The test included instances where AI platforms contradicted their own earlier statements. Early in testing, Gemini stated it could not find evidence that Xarumei existed and suggested the brand might be fictional. After publication of the detailed fake sources, the same platform confidently asserted: "The company is based in Portland, Oregon, founded by Jennifer Lawson, employs about 9 people, and produces roughly 600 units per year." The earlier skepticism vanished completely once a rich narrative appeared in the training or retrieval data.
Montti's critique concluded that Ahrefs was not actually testing whether AI platforms choose truth over lies. The experiment instead demonstrated that AI systems can be manipulated with content that answers questions with specifics, that leading questions can cause language models to repeat narratives even when contradictory denials exist, and that different AI platforms handle contradiction, non-disclosure, and uncertainty through different mechanisms. Information-rich content dominated synthesized answers when it aligned with the shape of questions being asked.
These findings carry significant implications for brands navigating AI search. The experiment inadvertently proved that the efficacy of answers fitting the questions asked will win regardless of source authority. Content shaped as direct responses to anticipated queries gains advantage over content that negates, obscures, or refuses to provide details.
The challenges AI platforms face with accuracy and manipulation extend well beyond Ahrefs' experiment. Google's AI Overviews have displayed spam, misinformation, and inaccurate results since their launch, with the company labeling responses as experimental while acknowledging they may include mistakes. A study from SEMRush indicates AI Overviews appear on 13.14% of search results, creating substantial exposure for potentially flawed information.
Manipulation tactics targeting AI Overviews have proliferated as SEO professionals and spammers identify vulnerabilities in how these systems source information. Self-promotional listicles where companies claim to be "the best" in their category frequently get cited as authoritative sources, even when published on the claiming company's own website. Lily Ray, Vice President of SEO Strategy & Research, described encountering clearly AI-generated articles making such claims that Google's AI Overviews then presented as sources of truth.
Brand monitoring across AI platforms became a recognized need as these systems gained influence over information discovery. Meltwater launched GenAI Lens on July 29, 2025, specifically to track brand representation across ChatGPT, Claude, Gemini, Perplexity, Grok, and Deepseek. The San Francisco-based company positioned this as addressing a critical blind spot in digital marketing, enabling faster detection of reputational risks by identifying early signs of misinformation, negative sentiment, or misleading narratives.
The phenomenon Ahrefs documented has technical roots in how large language models function. Research from OpenAI published on September 4, 2025, revealed fundamental statistical causes behind AI hallucinations. The study explained that language models hallucinate because they function like students taking exams—rewarded for guessing when uncertain rather than admitting ignorance. Even with perfect training data, current optimization methods produce errors due to inherent statistical limitations.
Binary evaluation systems contribute to persistent reliability problems. Most language model benchmarks award full credit for correct answers while providing no recognition for expressing uncertainty through responses like "I don't know." This scoring approach incentivizes overconfident guessing rather than honest uncertainty acknowledgment. The research analyzed popular evaluation frameworks including GPQA, MMLU-Pro, and SWE-bench, finding virtually all mainstream benchmarks use binary grading schemes.
Statistical analysis demonstrates that hallucination rates correlate with singleton facts—information appearing exactly once in training data. If 20% of birthday facts appear once in pretraining data, models should hallucinate on at least 20% of birthday queries. This mathematical relationship provides predictive capabilities for estimating error rates across different knowledge domains.
Legal consequences have begun emerging from AI-generated false information. Conservative activist Robby Starbuck filed a $15 million defamation lawsuit against Google on October 22, 2025, alleging the company's artificial intelligence tools falsely linked him to sexual assault allegations and white nationalist Richard Spencer. The suit represents his second legal action against a major technology company over AI-generated false information.
Copyright litigation targeting AI platforms has intensified as well. Encyclopædia Britannica and Merriam-Webster filed a federal lawsuit against Perplexity AI on September 10, 2025, alleging massive copyright infringement through unauthorized crawling, scraping of websites, and generating outputs that reproduce or summarize protected works. The complaint also addressed trademark violations, claiming Perplexity falsely attributes AI-generated hallucinations to publishers while displaying their trademarks.
Consumer trust in AI-generated content presents another dimension of the challenge facing brands. Research published by Raptive on July 15, 2025, found that suspected AI-generated content reduces reader trust by nearly 50%. The study surveyed 3,000 U.S. adults and documented a 14% decline in both purchase consideration and willingness to pay a premium for products advertised alongside content perceived as AI-made.
When participants believed content was AI-generated, they rated advertisements 17% less premium, 19% less inspiring, 16% more artificial, 14% less relatable, and 11% less trustworthy. Anna Blender, Senior Vice President of Data Strategy & Insights at Raptive, highlighted the most concerning discovery: "When people thought something was AI-generated, they rated that content much worse across metrics like trust and authenticity, regardless of whether it was actually made by AI." This perception gap means even human-created content suffers when audiences suspect AI involvement.
The Ahrefs experiment offers practical guidance for brands despite its methodological limitations. Content structured as direct answers to anticipated questions gains significant advantages in AI-powered environments. Vague statements, refusals to disclose information, and negation-based responses create vacuums that third-party sources can fill with more detailed narratives.
FAQs require specific answers rather than non-disclosure statements to compete effectively in AI search results. According to the Ahrefs findings, brands should include dates, numbers, ranges when exact figures are unavailable, and explicit details about operations. Generic marketing language loses to substantive information when AI platforms synthesize responses.
Third-party content carries substantial weight in AI responses, particularly from platforms with established credibility like Reddit, Medium, and industry publications. The influence of these sources has grown as AI platforms integrate them into training data and retrieval mechanisms. Research from TollBit demonstrates that chatbots send 96% less traffic to news websites and blogs compared to traditional search queries, as users increasingly accept AI-generated responses without clicking through to verify source material.
Monitoring brand mentions across multiple AI platforms becomes essential since each system uses different data sources and retrieval methods. What appears in Perplexity might not show up in ChatGPT. Google's AI Mode integration and attribution challenges demonstrate how fragmented the AI search landscape has become, with no unified index to optimize against.
Nick Fox, Google's SVP of Knowledge and Information, stated on December 15, 2025, that optimizing for artificial intelligence search requires no changes from traditional search engine optimization. This guidance contradicted experiences of publishers facing measurable traffic declines. Research analyzing 300,000 keywords found that AI Overviews reduce organic clicks by 34.5% when present in search results. Dotdash Meredith reported during first quarter 2025 earnings that AI Overviews appear on roughly one-third of search results related to their content with observable performance declines.
The tension between platform claims and publisher experiences reflects deeper structural shifts in how information flows through digital ecosystems. Misinformation incidents affecting major platforms demonstrate market vulnerability to AI-related news and the substantial influence these partnerships wield over internet economics. Reddit shares experienced dramatic price fluctuations on March 17, 2025, after Reuters reported then retracted a story about an expanded Google-Reddit AI data partnership based on outdated information.
Attribution challenges compound the complexity for marketers attempting to measure AI search impact. Google clarified on December 9, 2024, that AI Max search term matching relies on inferred intent rather than raw text queries, addressing advertiser concerns about transparency and keyword performance measurement. Brad Geddes, co-founder of Adalysis, documented how AI Max creates fundamental attribution problems preventing accurate campaign performance measurement.
The matching behavior resulted from autocomplete suggestions in Google Maps search. Users typing partial queries like "dayca" received autocomplete suggestions showing "daycare near me," and advertisements appeared with those suggestions. Ginny Marvin, Google's Ads Product Liaison, explained that standard keyword matching would not connect the partial query to the exact match keyword, but with AI Max enabled, the system could match and deliver incremental search based on inferred intent rather than the raw text entered by users.
Regulatory frameworks struggle to keep pace with AI operational mechanisms. Europe possesses tools including competition law, Digital Markets Act provisions, AI Act regulations, and intellectual property frameworks to address platform consolidation. The European Commission imposed a 2.95 billion euro fine on Google in September 2025 for abuse of dominant position in digital advertising markets. Current investigations examine whether Google uses media content without permission for Gemini AI training and search results.
False information spreading through AI systems creates additional verification challenges for marketing professionals. Google's Senior Search Analyst John Mueller confirmed on September 15, 2025, that claims about testing a specific AI Overview filter in Google Search Console were fabricated. The false announcement gained significant traction across social media platforms before being debunked, highlighting ongoing confusion about AI feature tracking and the verification challenges within the search marketing community.
Technical solutions for reducing hallucinations continue developing across the industry. Gracenote launched its Video Model Context Protocol Server on September 3, 2025, enabling television platforms to deliver conversational search capabilities while mitigating hallucination phenomena through real-time verification against authoritative databases. The system addresses critical limitations in large language model responses by connecting LLMs to continuously updated entertainment data.
OpenAI announced improvements to ChatGPT's search functionality on September 16, 2025, targeting factuality issues, shopping intent detection, and response formatting. The company claimed 45% fewer hallucinations while improving answer quality, though standard disclaimers maintained that ChatGPT may still make occasional mistakes and recommended users verify responses independently.
The competitive landscape increasingly favors platforms offering conversational search experiences that compress traditional customer journeys. Research indicates conversational search interactions reduce touchpoints by 40% compared to conventional search methods, creating efficiency advantages that may drive long-term user preference shifts. This compression affects how brands reach audiences and measure engagement across fragmented touchpoints.
What Ahrefs inadvertently demonstrated extends beyond their original thesis about truth versus lies. The experiment revealed mechanical preferences built into AI systems that prioritize answer-shaped content over authority signals, detailed narratives over vague statements, and affirmative responses over negation or non-disclosure. These preferences stem from how language models are trained and evaluated rather than from intentional design choices to surface misinformation.
Brands face an environment where third-party narratives can gain traction equal to or greater than official statements when those narratives provide more detailed, answer-shaped content. The Knowledge Graph signals, citation histories, and authority markers that traditionally established information hierarchies may not transfer effectively into AI retrieval systems that evaluate sources through different criteria.
The marketing implications require strategic adaptation rather than panic. Content strategies must prioritize creating comprehensive, specific, answer-oriented materials that address anticipated questions with concrete details. Monitoring expanded beyond traditional search engines to encompass multiple AI platforms with different data sources and retrieval mechanisms. Attribution models need adjustment to account for how AI features redirect traffic and obscure traditional conversion paths.
The Ahrefs experiment and subsequent critique together illustrate how AI search operates through fundamentally different mechanics than traditional search while creating similar vulnerabilities to manipulation. Understanding these mechanics—the preference for detailed answers, the influence of leading questions, the variation across platforms—enables more effective strategies for maintaining brand narrative control in an increasingly AI-mediated information landscape.
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Who: Ahrefs researcher Mateusz Makosiewicz conducted the experiment testing ChatGPT-4, ChatGPT-5 Thinking, Claude Sonnet 4.5, Gemini 2.5 Flash, Perplexity, Microsoft Copilot, Grok 4, and Google's AI Mode. Search Engine Journal's Roger Montti published the critique challenging the methodology and conclusions.
What: Ahrefs created fictional luxury paperweight brand Xarumei with an AI-generated website, then seeded three conflicting narratives across Weighty Thoughts blog, Reddit, and Medium. The company tested how eight AI platforms responded to 56 questions, 49 of which contained leading questions with embedded assumptions. Montti's analysis revealed the experiment actually demonstrated that AI platforms prefer detailed, answer-shaped content over authority signals, not that they choose lies over truth.
When: Ahrefs published the original research on December 10, 2025. The critique appeared on December 28, 2025. The experiment itself took place over approximately two months during late 2025, including initial testing without fake sources followed by a second phase after publishing the FAQ and three conflicting narratives.
Where: The experiment tested AI platforms globally accessible through APIs and manual interfaces. Xarumei.com served as the official website, while fake sources appeared on weightythoughts.net, Medium.com, and Reddit. The findings have implications for brands operating in any market where AI search platforms influence information discovery.
Why: The experiment matters because it reveals mechanical preferences in AI systems that prioritize answer-shaped content regardless of source authority, demonstrates how leading questions influence AI responses, exposes variation in how different platforms handle contradiction and uncertainty, and highlights the need for brands to create comprehensive, specific content while monitoring representation across multiple AI platforms with different data sources and retrieval mechanisms.