Shadow library scraped 86 million Spotify tracks for preservation
Anna's Archive distributed 256 million Spotify metadata rows and 86 million audio files totaling 300 terabytes, representing 99.6% of platform listens.

Anna's Archive distributed 256 million Spotify metadata rows and 86 million audio files totaling 300 terabytes, representing 99.6% of platform listens.
Shadow library project Anna's Archive announced on December 20, 2025, that it successfully scraped Spotify's music catalog, releasing 256 million rows of track metadata and preparing to distribute 86 million audio files representing approximately 99.6 percent of all listens on the streaming platform. The operation totals roughly 300 terabytes of data distributed through torrent files.
According to the announcement published on Anna's Archive blog, the project scraped the metadata and music files directly from Spotify's servers using undisclosed technical methods. The distribution represents what the organization characterizes as the world's first "preservation archive" for music that can be easily mirrored by anyone with sufficient storage capacity.
The metadata database contains information for an estimated 99.9 percent of tracks available on Spotify. Anna's Archive released this component first through torrents on its dedicated torrents page in December 2025. Music files will follow in subsequent releases ordered by popularity, along with additional file metadata and album artwork.
Spotify responded to the scraping operation by disabling accounts identified as responsible for the data extraction. According to a statement provided in the source materials, the company said it has "stood with the artist community against piracy" since its founding and is "actively working with our industry partners to protect creators and defend their rights."
The technical implementation involved multiple quality tiers based on Spotify's internal popularity metric. For tracks with popularity scores above zero, Anna's Archive preserved the original OGG Vorbis format at 160 kilobits per second. Songs with popularity scores of zero were reencoded to OGG Opus at 75 kilobits per second, which the organization states sounds identical to most listeners but may be noticeable to experts.
The dataset includes 256 million total tracks available on Spotify. Anna's Archive preserved 86 million of these as audio files, representing approximately 37 percent of total songs but accounting for 99.6 percent of actual listening activity on the platform. The organization prioritized tracks based on Spotify's proprietary popularity algorithm, which calculates scores between 0 and 100 based primarily on total plays and recency of those plays.
According to metadata analysis published by Anna's Archive, tracks with popularity scores between 50 and 80 account for the majority of listens despite representing only approximately 0.1 percent of available songs. The organization identified that 70 percent of songs on Spotify have fewer than 1,000 streams. The top three songs as of the data collection period—"Die With A Smile" by Lady Gaga and Bruno Mars, "BIRDS OF A FEATHER" by Billie Eilish, and "DtMF" by Bad Bunny—have accumulated billions of streams individually.
The metadata component constitutes less than 200 gigabytes compressed and includes nearly lossless representations of Spotify API JSON responses converted to queryable SQLite databases. Secondary metadata covering audio analysis totals 4 terabytes compressed. The organization took care during conversion to ensure minimal data loss from original API responses through JSON reconstruction validation.
Anna's Archive added embedded metadata to each audio file that was absent in Spotify's original format. This includes track titles, URLs, International Standard Recording Codes (ISRCs), Universal Product Codes (UPCs), album artwork, and replaygain information. The organization stripped an invalid OGG data packet that Spotify prepends to every track file, preserving this information separately for users who wish to reconstruct original Spotify files.
The database contains 186 million unique ISRCs, substantially exceeding the 5 million unique codes cataloged by MusicBrainz. This makes Anna's Archive's dataset the largest publicly available music metadata database according to comparative analysis published in the announcement. Other metadata sources typically contain between 50 million and 150 million tracks with less comprehensive annotation.
Buy ads on PPC Land. PPC Land has standard and native ad formats via major DSPs and ad platforms like Google Ads. Via an auction CPM, you can reach industry professionals.
For tracks with popularity greater than zero, the organization archived files representing close to all tracks available on the platform. The cutoff date was July 2025, meaning content released after that date may not appear in the collection, though some later releases are present. The organization stopped archiving the long tail of zero-popularity tracks due to diminishing preservation value relative to storage requirements, which would have exceeded 700 additional terabytes for marginal benefit.
The announcement states that the organization discovered the scraping method "a while ago" but provides no specific timeline for when systematic collection began. The project team decided to build a music archive primarily aimed at preservation after identifying what they characterize as significant gaps in existing music preservation efforts.
Anna's Archive identified three major issues with current music preservation approaches. First, excessive focus on the most popular artists leaves a long tail of music preserved only when single individuals care enough to share specific works, often with poor seeding infrastructure. Second, audiophile communities prioritize highest possible quality formats like lossless FLAC, inflating file sizes and making comprehensive archival impractical. Third, no authoritative torrent list exists aggregating all music humanity has produced, comparable to Anna's Archive's existing book torrent aggregations from Library Genesis, Sci-Hub, and Z-Library.
The organization acknowledges that Spotify does not contain all music in existence but describes the platform as "a great start" for building a preservation archive. The announcement emphasizes that this represents a humble attempt to create such infrastructure for music, similar to existing shadow library preservation efforts for textual content.
The data will be released in stages through Anna's Archive's torrents infrastructure. The first stage, metadata distribution, completed in December 2025. Music files will follow in popularity order, followed by additional file metadata containing torrent paths and checksums, then album artwork, and finally .zstdpatch files enabling reconstruction of original Spotify files before metadata embedding.
The organization currently positions this as a torrents-only preservation archive but solicited feedback about whether users would want individual file downloading capabilities added to Anna's Archive's main interface. The announcement includes direct requests for user input on this potential feature expansion.
Anna's Archive operates as a non-profit shadow library project that aggregates and preserves content from various sources. The organization launched in November 2022 shortly after law enforcement seized Z-Library domains and arrested its alleged operators. Anna's Archive emerged from the Pirate Library Mirror project, which completed a full Z-Library copy in September 2022.
The site describes itself as having two goals: backing up all knowledge and culture of humanity, and making this accessible to anyone worldwide. All code and data are released as completely open source. The organization's typical focus centers on textual content including books, papers, comics, and magazines. According to its FAQ page, the project explained in a blog post titled "The critical window of shadow libraries" that it prioritizes text because of its highest information density among media types.
The Spotify scraping operation represents a departure from this textual focus. According to the December 20 announcement, the organization's mission of "preserving humanity's knowledge and culture" does not distinguish among media types, and sometimes opportunities arise outside the textual domain. The team characterized the Spotify collection as one such opportunity.
The organization's infrastructure relies on distributed preservation through torrenting, which creates many copies around the world and makes the collection resilient to takedowns. Anna's Archive currently preserves content from shadow libraries including Sci-Hub and Library Genesis that already offer bulk distribution, while also "liberating" libraries that do not provide bulk downloads such as Z-Library, or that are not shadow libraries at all including Internet Archive and DuXiu.
The organization maintains official domains at annas-archive.org, annas-archive.se, and annas-archive.li. Multiple countries have blocked access to these domains. According to Wikipedia documentation, Anna's Archive has faced blocking orders in Italy as of January 2024, the Netherlands as of March 2024, the United Kingdom as of December 2024, Belgium as of July 2025, and Germany as of October 2025.
The United States Trade Representative included Anna's Archive domains in its annual Notorious Markets List since 2023, describing the site as related to Sci-Hub and Library Genesis. The Association of American Publishers identified the site as infringing in comments submitted to the Office in July 2023, analyzing cryptocurrency wallets to determine the project had received over $29,000 in funds as of that date.
Anna's Archive faced a lawsuit filed by OCLC in January 2024 after the shadow library scraped WorldCat, the world's largest bibliographic database. OCLC sought over $5 million in damages and an injunction to stop scraping or sharing its proprietary data. The organization described the WorldCat scrape in October 2023 as "a major milestone in mapping out all the books in the world." As of November 2025, OCLC dropped its demand for damages, focusing efforts on obtaining an injunction compelling third-party intermediaries to stop sharing the data.
Internal emails unsealed in February 2025 during copyright litigation against Meta in California federal court revealed that the company downloaded over 81 terabytes of data through Anna's Archive torrents for artificial intelligence model training. Authors including Richard Kadrey, Sarah Silverman, and Christopher Golden alleged that Meta CEO Mark Zuckerberg personally authorized the use of shadow libraries for AI training. In June 2025, Judge Vince Chhabria partially ruled in favor of Meta, finding the training "highly transformative" and therefore fair use, while noting the plaintiffs failed to develop strong arguments about market dilution.
Google removed 749 million Anna's Archive URLs from search results by November 2025, representing 5 percent of all takedown requests sent to the search engine since 2012. These requests originated from over 1,000 authors and publishers. The site ranks among Google Search's ten most reported domains for DMCA takedowns as of June 2024.
Anna's Archive generates revenue through paid membership tiers offering faster download speeds. The organization describes itself as nonprofit, claiming that membership fees and donations fund mostly servers, storage, and bandwidth, with no money going to team members personally. The site awards memberships and monetary bounties to some volunteer contributors.
The organization offers high-speed access to its full collection via SFTP to groups training large language models in exchange for large contributions of money or data. As of January 2025, the shadow library provided such access to approximately 30 companies, primarily based in China, including both LLM companies and data brokers. DeepSeek's VL model was partly trained on ebook data obtained from the site.
Anna has justified opposition to copyright on ethical grounds, stating that preserving and hosting files is "morally right" and that shadow librarians believe "information wants to be free." In February 2025, the organization urged copyright law reform as a matter of national security, proposing that Western countries create legal carveouts for text and data mining to remain ahead in what it characterized as an AI arms race.
Subscribe PPC Land newsletter ✉️ for similar stories like this one
The organization cites programmer and information activist Aaron Swartz as inspiration for its metadata collection efforts. The site recommends Swartz's writings, Stephen Witt's "How Music Got Free," and Michele Boldrin and David K. Levine's "Against Intellectual Monopoly" as resources supporting its philosophical approach to copyright and intellectual property.
The Spotify scraping operation intersects with broader tensions in digital advertising and content markets over unauthorized data collection for commercial purposes. Meta faced scrutiny after leaked documents revealed systematic scraping of approximately 6 million unique websites for AI model training, including news organizations, educational platforms, and copyrighted content repositories. Google filed lawsuits against companies scraping its search results while simultaneously conducting massive web scraping operations for AI training, exposing asymmetrical power dynamics in content distribution.
Music streaming platforms have faced copyright challenges in advertising and marketing contexts. Sony Music Entertainment filed a copyright infringement lawsuit against Designer Shoe Warehouse in August 2025, alleging the retailer systematically used copyrighted musical recordings in social media marketing campaigns without proper licensing on TikTok and Instagram platforms.
The legal landscape surrounding AI training data and copyright remains contested. A federal judge ruled in June 2025 that Meta's use of 666 copyrighted books to train Llama large language models constitutes fair use, though the decision applied only to specific plaintiffs and left other authors free to pursue copyright claims. The U.S. Copyright Office released a major report in May 2025 analyzing how generative AI development implicates copyright law, establishing a nuanced framework for case-by-case evaluation rather than sweeping determinations.
Venture capital firm Andreessen Horowitz argued in October 2023 comments to the Copyright Office that using copyrighted content to train AI models constitutes fair use because training extracts statistical patterns rather than storing copyrighted content, warning that licensing frameworks would prove administratively impossible given the billions of text pieces involved. Professor Carys Craig's research published in the Chicago-Kent Law Review cautioned in August 2024 against using copyright law as the primary AI regulation tool, arguing that requiring permissions could limit competition by creating cost-prohibitive barriers favoring powerful market players.
Vermont Senator Peter Welch introduced the TRAIN Act in July 2025, establishing an administrative subpoena mechanism allowing copyright owners to determine which protected works were used to train artificial intelligence models, representing a middle-ground approach between expansive copyright enforcement and unrestricted AI development.
The music streaming industry has navigated complex regulatory environments globally. Spotify announced plans to exit Uruguay in December 2023 over copyright law changes requiring the company to pay twice for the same songs—once to record labels and publishers, and again to a government-created fund. Spotify reported strong fourth quarter 2023 advertising performance in February 2024, with ad revenue growing 12 percent year-over-year driven by double-digit music advertising growth and healthy podcast advertising expansion.
The Anna's Archive metadata analysis revealed technical details about Spotify's catalog composition and user behavior patterns. Songs grouped by duration show peaks at whole minutes, particularly 2:00, 3:00, and 4:00, though the organization requested user input to explain this phenomenon. The dataset shows 221.4 million tracks marked as explicit content versus 34.6 million clean versions.
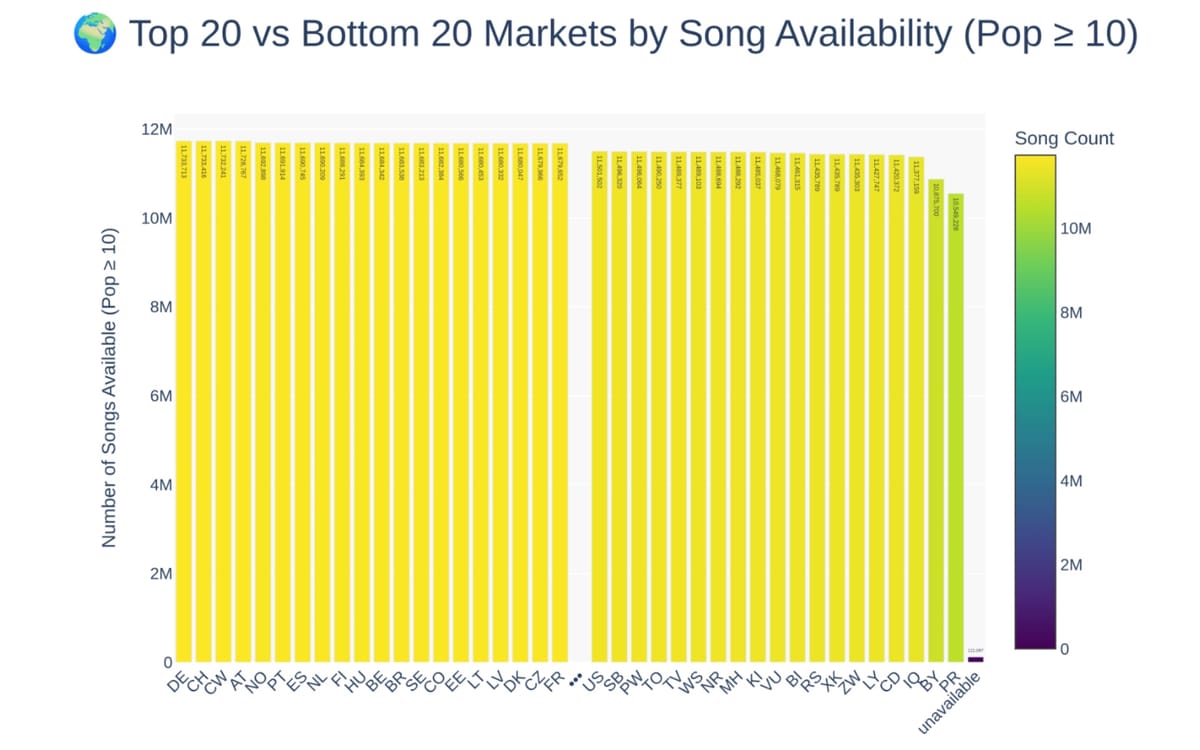
Market availability varies significantly across Spotify's geographic distribution. The analysis shows that filtering to only popular songs reveals differences in market availability that appear flat when examining all tracks regardless of popularity. Spotify provides genre lists per artist rather than per song, with the most common specific genres distributed across hundreds of distinct classifications.
Album release data demonstrates accelerating content addition to Spotify over time, with the organization noting that much recent growth likely stems from automatically generated content. The prevalence of procedurally and AI-generated material complicates efforts to identify valuable content, according to the analysis. The majority of tracks on Spotify exist as singles rather than as components of full albums.
Audio features scraped from Spotify's API show technical characteristics across the catalog. Loudness correlates with energy metrics. Beats per minute follows a normal distribution with a mean around 120. The dataset includes approximately 40 million audio analysis API responses, though many songs do not have audio analysis available, returning 404 errors.
The playlist database contains 6.6 million playlists representing 1.7 billion playlist track entries. Most playlists with fewer than 1,000 followers were excluded from the collection. The organization also scraped approximately 700,000 audiobook entries, 20 million audiobook chapter entries, 5 million podcast show entries, and 54 million podcast episode entries, though these collections are incomplete.
The technical architecture uses Anna's Archive Containers format, a standardization system created by the organization for distributing files across multiple torrents. This differs from Advanced Audio Coding format despite the AAC acronym. Files are indexed into directories using filename prefixes, with metadata stored separately from audio data to enable efficient querying and reconstruction.
The organization acknowledges a known bug where the REPLAYGAIN_ALBUM_PEAK vorbiscomment tag value contains copied data from REPLAYGAIN_ALBUM_GAIN instead of the correct peak value for many files. Users seeking to reconstruct original Spotify files can utilize the .zstdpatch archive that will be released in later distribution stages.
The announcement includes example queries demonstrating the true shuffle functionality across all Spotify tracks, contrasting with user complaints about Spotify's native shuffle algorithm. The organization provides both unfiltered true shuffle playlists and versions filtered to only somewhat popular songs, showcasing the database's queryability.
The metadata includes track-level information absent from Spotify's public API for many use cases. Each track exists in exactly one album, but tracks and albums can have multiple artists. The database stores artist genres as separate table entries since Spotify provides genre lists per artist. Available markets are stored in a separate table with comma-separated ISO 3166-1 alpha-2 country codes to save space through deduplication.
Artist metadata includes follower counts and popularity scores calculated from track popularity. Album metadata contains label information, copyright notices, release dates with precision indicators, and Universal Product Codes where available. Track metadata includes preview URLs, disc numbers, track numbers, duration in milliseconds, explicit content flags, and available markets.
The organization stripped invalid OGG packets that Spotify prepends to track files but preserved this data separately. These packets contain unknown information plus replaygain values stored as float32 little-endian values at specific byte offsets. The archive's SQLite databases enable reconstruction of original Spotify API JSON responses with minimal exceptions.
Telegram suspended Anna's Archive's channel in January 2025 for copyright infringement despite precautions to avoid infringing posts. Z-Library's Telegram channel faced suspension the same week. Neither organization received alerts about the action, which was speculated to link to legal action by an Indian court.
The Spotify preservation effort represents the organization's largest departure from textual content preservation. Anna's Archive typically focuses on books, papers, comics, and magazines aggregated from various shadow libraries and official library collections. The organization's main search interface as of December 2025 claims to index 61.7 million books and 95.7 million papers, describing itself as "the largest truly open library in human history."
The project team explicitly requested community feedback on whether to add individual file downloading capabilities to Anna's Archive's main interface beyond the current torrents-only distribution model. The announcement concludes by requesting help preserving files through donations and torrent seeding, emphasizing that humanity's musical heritage faces threats from natural disasters, wars, budget cuts, and other catastrophes.
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Subscribe PPC Land newsletter ✉️ for similar stories like this one
Who: Anna's Archive, a non-profit shadow library project launched in November 2022 by pseudonymous operator Anna, scraped Spotify's music catalog. Spotify responded by disabling accounts responsible for the data extraction.
What: The organization distributed 256 million rows of track metadata and prepared distribution of 86 million audio files totaling approximately 300 terabytes, representing 99.6 percent of all listening activity on Spotify. The metadata database covers an estimated 99.9 percent of tracks available on the platform.
When: Anna's Archive announced the scraping operation on December 20, 2025, through its blog. The data collection covered content through July 2025. Metadata distribution began in December 2025, with music files planned for subsequent release in popularity order.
Where: The scraping targeted Spotify's servers directly using undisclosed technical methods. Distribution occurs globally through torrent infrastructure, though multiple countries including Italy, the Netherlands, the United Kingdom, Belgium, and Germany have blocked access to Anna's Archive domains.
Why: Anna's Archive characterized the effort as addressing three major gaps in music preservation: excessive focus on popular artists leaving a long tail poorly preserved, audiophile communities prioritizing impractically large lossless formats, and absence of an authoritative aggregated torrent list for all music. The organization describes the operation as a "humble attempt" to build a preservation archive for music comparable to its existing efforts preserving textual content.